



一、背景与目标
AI 应用开发正从"单次对话"走向"编排式智能体"。Dify、LangFlow、FastGPT 等平台证明了可视化工作流 + LLM 的产品形态已被市场验证。我们的目标是在一个成熟开源底座上进行二次开发,快速构建自研的可视化 AI 工作流编排平台,核心诉求包括:自主可控的架构演进能力、面向企业场景的深度定制能力、以及差异化的产品竞争力。
二、同类产品技术栈全景分析
2.1 Dify — 最值得二次开发的底座
Dify 是当前最成熟的开源 AI 应用开发平台之一(GitHub 90k+ Stars),采用 Python/Flask 后端 + Next.js 前端的架构。其后端为模块化单体架构(DDD 分层),部署为 11 个 Docker 容器;工作流引擎基于 DAG + 事件驱动观察者模式实现;前端使用 React Flow 构建可视化编辑器;数据层使用 PostgreSQL + Redis + Celery;向量数据库支持 Weaviate、Milvus、Qdrant 等 8 种可插拔方案。Dify 拥有完整的插件体系(Tool / Model / Extension / Agent Strategy 四类插件)和 Python SDK,每个 LLM 提供商本身就是插件。
Dify 的核心优势在于架构清晰、插件生态完善、社区活跃度高。主要局限包括:自托管部署较重(11 容器)、原生工具集成数量有限(约 50 个 vs n8n 的 400+)、RAG 质量需手动调优、MCP 支持仍在成熟中、云端按消息计费在规模化时成本较高。
2.2 LangFlow — 社区最大,偏实验性
LangFlow(GitHub 150k Stars)采用 Python/FastAPI + React 技术栈,最大特色是代码导出能力——可视化编排可一键生成 Python 脚本。其 DAG 执行引擎支持条件分支和循环,底层集成 LangChain 生态。适合快速原型验证,但在生产级多租户、权限管控等方面不如 Dify 成熟。
2.3 FastGPT — 全栈 Next.js + MongoDB
FastGPT(GitHub 20k+ Stars)是少见的用 Next.js 同时承担前后端的方案,数据库选用 MongoDB。优点是部署简单、中文社区友好、知识库管理开箱即用;缺点是 Node.js 后端在 AI 生态(模型调用、向量化)中不如 Python 丰富,MongoDB 在复杂工作流状态管理上不如关系型数据库灵活。
2.4 RAGFlow — RAG 专精
RAGFlow(GitHub 83k Stars)深耕文档理解与检索增强生成,在文档解析(PDF 表格、OCR、版面分析)方面做到了业界领先水平。但其工作流编排能力相对简单,更适合作为 RAG 子系统引入而非整体底座。
2.5 Bisheng — 企业治理最强
Bisheng 在 RBAC、SSO/LDAP、多数据库等企业治理方面最为完善,但基础设施最重,二次开发门槛较高。适合大型企业直接采购部署,不太适合作为轻量二次开发的起点。
2.6 MaxKB — 最轻量运维
MaxKB 采用 Vue + Django + PostgreSQL/pgvector 单数据库设计,运维成本最低。但功能深度和社区生态有限,适合小型项目快速上线。
2.7 综合对比矩阵
| 维度 | Dify | LangFlow | FastGPT | RAGFlow | Bisheng | MaxKB |
| ------ | -------------------- | ----------------- | --------------- | --------------- | ------------------ | ------------- |
| 后端语言 | Python/Flask | Python/FastAPI | Node.js/Next.js | Python | Python | Python/Django |
| 前端框架 | Next.js + React Flow | React | Next.js | Vue | Vue | Vue |
| 数据库 | PostgreSQL + Redis | SQLite/PostgreSQL | MongoDB | PostgreSQL + ES | PostgreSQL + Redis | PostgreSQL |
| 工作流引擎 | DAG + 事件驱动 | DAG + LangChain | 简单流程 | 简单流程 | DAG | 简单流程 |
| 插件系统 | 4 类插件 + SDK | 自定义组件 | 插件市场 | 有限 | 插件化 | 有限 |
| 可视化编辑器 | React Flow | React Flow | 自研 | 简单 | AntV X6 | 自研 |
| 多租户 | 支持 | 基础 | 支持 | 支持 | 强 | 基础 |
| 部署复杂度 | 中(11容器) | 低 | 低 | 中 | 高 | 低 |
| 社区活跃度 | ★★★★★ | ★★★★★ | ★★★ | ★★★★ | ★★★ | ★★ |
三、底座选型结论:以 Dify 为底座
综合评估后,推荐以 Dify 作为二次开发底座,理由如下:
第一,Python 后端与我们"基于 Python 语言开发"的要求完全吻合,AI/ML 生态最丰富。第二,模块化单体架构(DDD 分层)便于理解和修改,不需要一开始就面对微服务的复杂度。第三,插件体系最完善——四类插件覆盖工具、模型、扩展、Agent 策略,且每个 LLM Provider 本身就是插件,这为深度定制提供了良好的扩展点。第四,React Flow 构建的可视化编辑器是目前最成熟的节点式编辑方案,社区资源丰富。第五,PostgreSQL + Redis + Celery 的技术组合在生产环境中久经验证。
同时需要正视 Dify 的不足,这些正是我们二次开发要解决的问题:自托管过重需要轻量化改造、工具集成数量有限需要补齐、RAG 质量需要系统性提升、MCP 支持需要完善。
四、产品设计结构
4.1 产品全景功能架构
产品整体划分为六大功能域,每个域下包含具体功能模块。
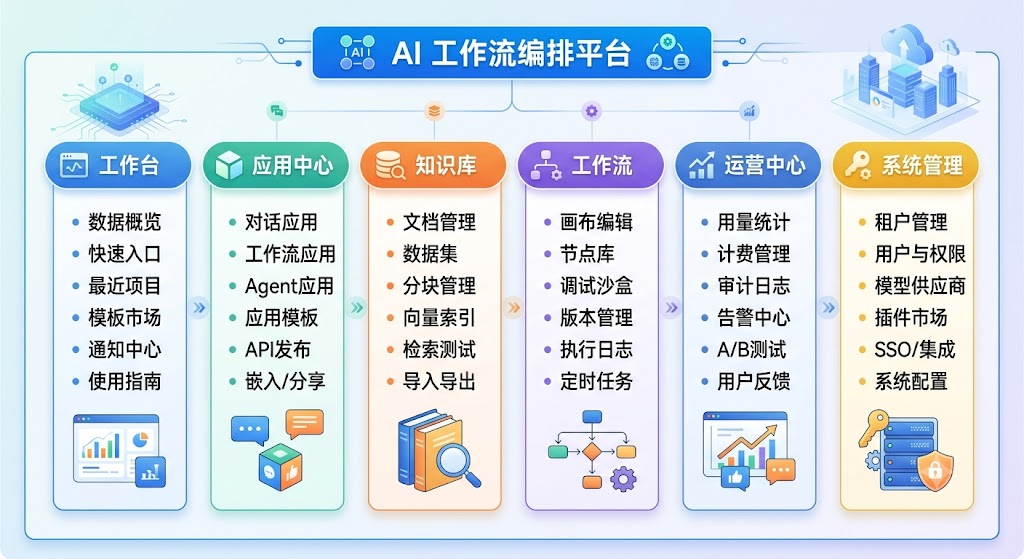
4.2 用户角色与权限矩阵
平台定义四种核心角色,每个角色拥有不同的功能访问权限。
| 功能域 | 平台管理员 | 租户管理员 | 开发者 | 普通用户 |
| ------- | ----- | ----- | ----- | ---- |
| 工作台 | 全局视图 | 租户视图 | 个人视图 | 个人视图 |
| 应用创建/编辑 | 全部 | 本租户全部 | 本人创建 | 仅使用 |
| 知识库管理 | 全部 | 本租户全部 | 本人创建 | 仅查询 |
| 工作流设计 | 全部 | 本租户全部 | 本人创建 | 只读 |
| 模型供应商配置 | 全局配置 | 租户级配置 | 选择使用 | 不可见 |
| 插件安装/管理 | 全局 | 本租户 | 开发/上传 | 使用 |
| 计费/用量 | 全局账单 | 租户账单 | 个人用量 | 个人用量 |
| 用户管理 | 全平台 | 本租户成员 | — | — |
| 审计日志 | 全平台 | 本租户 | 本人操作 | — |
| 系统配置 | 全部 | 本租户配置 | — | — |
4.3 核心页面与交互流程
应用创建流程:用户从工作台进入应用中心,选择应用类型(对话型 / 工作流型 / Agent 型),系统提供空白画布和模板两种入口。选择模板后进入工作流编辑器,用户在画布上拖拽节点、连线、配置参数。编辑完成后可进入调试沙盒测试,调试通过后发布为 API / 嵌入式对话窗口 / 分享链接。
知识库构建流程:用户上传文档(支持 PDF、Word、Markdown、TXT、网页 URL 等格式)→ 系统自动解析并展示解析结果 → 用户选择分块策略(自动 / 手动调整分块边界)→ 选择 Embedding 模型生成向量 → 入库完成后可在"检索测试"页面验证召回效果 → 在工作流节点中引用该知识库。
工作流执行流程:用户触发工作流(手动 / API / 定时任务)→ 引擎按 DAG 拓扑排序依次执行节点 → 每个节点的输入/输出通过 SSE 实时推送到前端画布 → 节点状态以颜色标识(灰=等待、蓝=执行中、绿=成功、红=失败)→ 执行完成后生成执行报告,包含每个节点的耗时、Token 消耗、输入输出详情。
4.4 工作流节点类型体系
节点是工作流的最小执行单元,平台提供以下内置节点类型,同时支持用户通过插件扩展自定义节点。
基础节点:Start(入口,定义输入变量)、End(出口,定义输出格式)、Variable Assign(变量赋值)。
逻辑控制节点:IF/ELSE(条件分支)、Switch(多路分支)、For-Each(循环遍历)、While(条件循环)、Parallel(并行执行)、Merge(汇合等待)、Sub-Workflow(调用子工作流)。
AI 节点:LLM Call(大模型调用,支持 Prompt 模板和变量注入)、Knowledge Retrieval(知识库检索)、Question Classifier(意图分类)、Agent(智能体节点,支持工具调用和多轮推理)。
数据处理节点:Code(Python/JS 代码片段)、HTTP Request(API 调用)、JSON Parse(JSON 解析转换)、Text Transform(文本处理)、File Read/Write(文件读写)。
集成节点:Tool(调用插件工具)、Webhook Trigger(Webhook 触发器)、MCP Tool(调用 MCP 协议工具)、Notification(消息通知:邮件/钉钉/飞书/企微)。
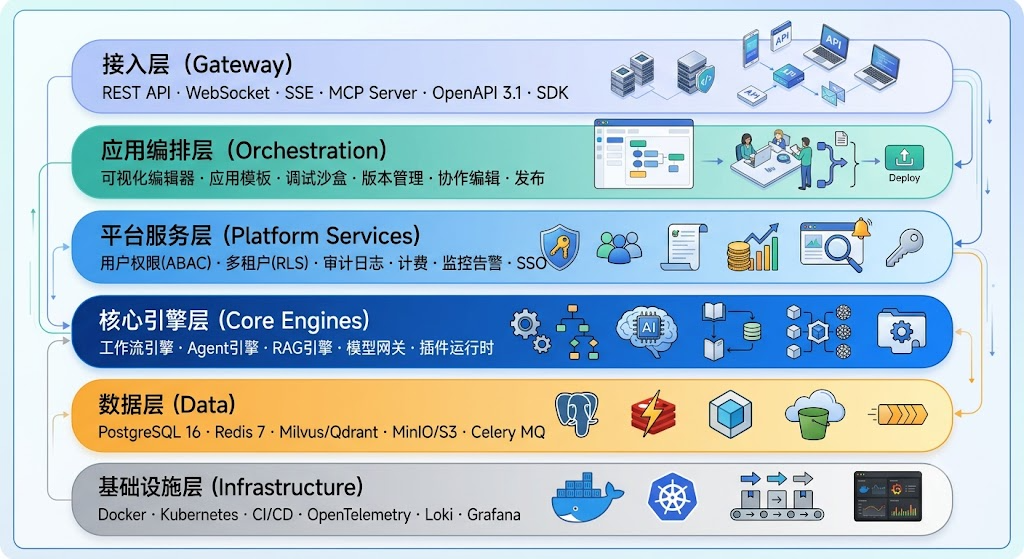
五、分层架构设计
整体架构分为六层,从下到上依次为:基础设施层、数据层、核心引擎层、平台服务层、应用编排层、接入层。每层职责清晰、接口明确,支持独立演进和水平扩展。
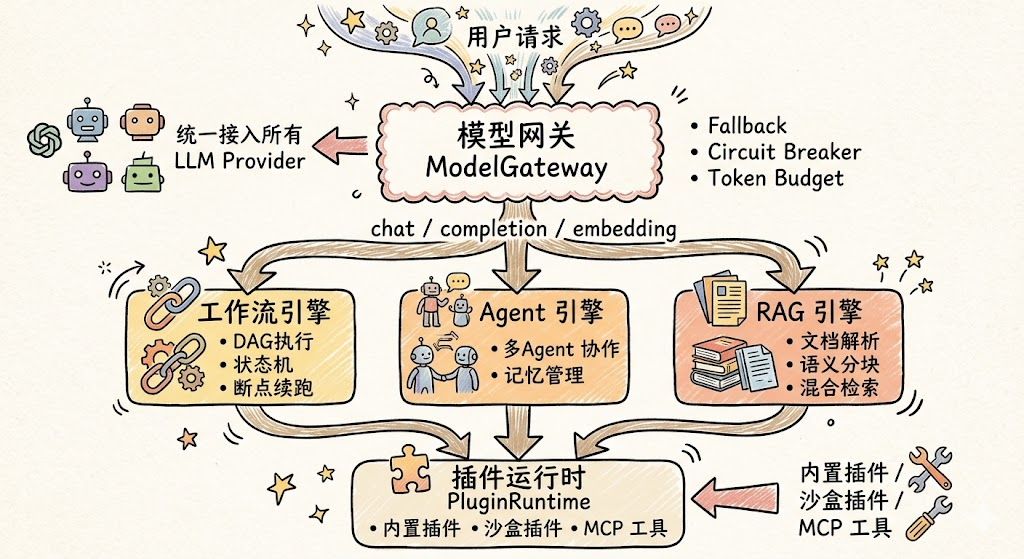
5.1 核心引擎层数据流
核心引擎层是整个平台的大脑,五个子引擎之间的数据流关系如下:
5.2 基础设施层
基础设施层负责运行环境的标准化和运维自动化。容器编排推荐 Docker Compose(开发/测试环境)+ Kubernetes(生产环境),CI/CD 采用 GitHub Actions 或 GitLab CI 实现自动化构建和部署。日志聚合使用 ELK Stack(Elasticsearch + Logstash + Kibana)或更轻量的 Loki + Grafana 方案。链路追踪引入 OpenTelemetry SDK,在 Python 后端中通过装饰器自动注入 trace_id,实现工作流执行全链路可观测。
关键改进点:Dify 原始部署包含 11 个容器,对中小团队偏重。二次开发时应提供"精简部署"模式——合并 API Server 和 Worker 为单进程(通过配置切换),将 Sandbox 从独立 Go 服务改为 Python subprocess 隔离(使用 nsjail 或 bubblewrap),将目标容器数压缩至 5-6 个。
5.3 数据层
数据层统一管理平台的持久化存储。PostgreSQL 作为主数据库,存储用户、工作流定义、执行记录、应用配置等结构化数据,使用 Alembic 做数据库迁移管理。Redis 承担三重角色:缓存层(模型响应缓存、会话状态缓存)、消息总线(Pub/Sub 用于工作流实时状态推送)、以及 Celery 的 Broker。
向量数据库采用可插拔设计,默认集成 Milvus 2.4.x(自建首选,GPU 加速,支持十亿级向量)和 Qdrant 1.12.x(轻量部署首选),通过统一接口 VectorStoreProvider ABC 屏蔽底层差异。对象存储使用 MinIO(自建)或 S3 兼容服务,存放文档、图片、模型产物等非结构化数据。
关键改进点:在 Dify 原有基础上引入 Celery Beat 实现定时工作流触发;增加 Redis Streams 作为事件溯源通道,支持工作流执行的完整回溯和重放。
5.4 核心引擎层 — 最关键的定制层
这是整个平台的大脑,包含五个子引擎,每个都是独立的二次开发重点。
5.4.1 工作流引擎(Workflow Engine)
Dify 的工作流引擎基于 DAG 拓扑排序执行,支持并行分支和条件路由。二次开发需要在以下方面增强:
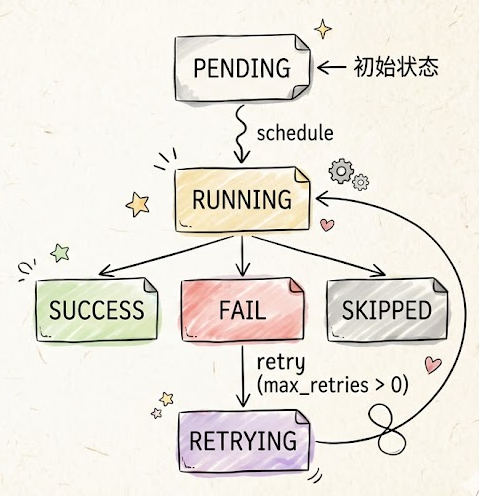
引入 transitions 库为每个节点建立显式状态机(pending → running → success/failed/skipped),使节点生命周期可追踪、可恢复。增加子工作流(Sub-workflow)支持,允许一个节点触发另一个完整工作流的执行,实现流程复用和嵌套编排。增加循环控制节点(For-Each / While),这在复杂数据处理场景中是刚需。引入断点续跑机制——将中间状态持久化到 PostgreSQL,当 Worker 异常退出后可从最近的成功节点恢复执行,而非从头开始。
执行模型上,保留 Celery 作为异步任务队列,但增加基于 asyncio 的轻量执行器用于 I/O 密集型的 LLM 调用节点,避免 Celery Worker 被大量等待 API 响应的任务阻塞。
工作流引擎节点状态机:
5.4.2 Agent 引擎(Agent Engine)
在 Dify 的 Agent Strategy 插件基础上,构建更灵活的 Agent 框架。核心改进包括:支持多 Agent 协作模式(Orchestrator-Worker、Debate、Pipeline 三种预置模式),通过 AgentProtocol ABC 定义 Agent 间通信契约。引入工具选择推理(Tool Selection Reasoning),让 Agent 在选择工具前先进行一轮思考,提高工具调用的准确率。增加记忆管理层,支持短期记忆(当前对话)、中期记忆(跨对话摘要)、长期记忆(向量化的历史交互),通过 MemoryManager 统一管理。
5.4.3 RAG 引擎(RAG Engine)
Dify 原生 RAG 能力基础够用但不够强。二次开发需要系统性提升:
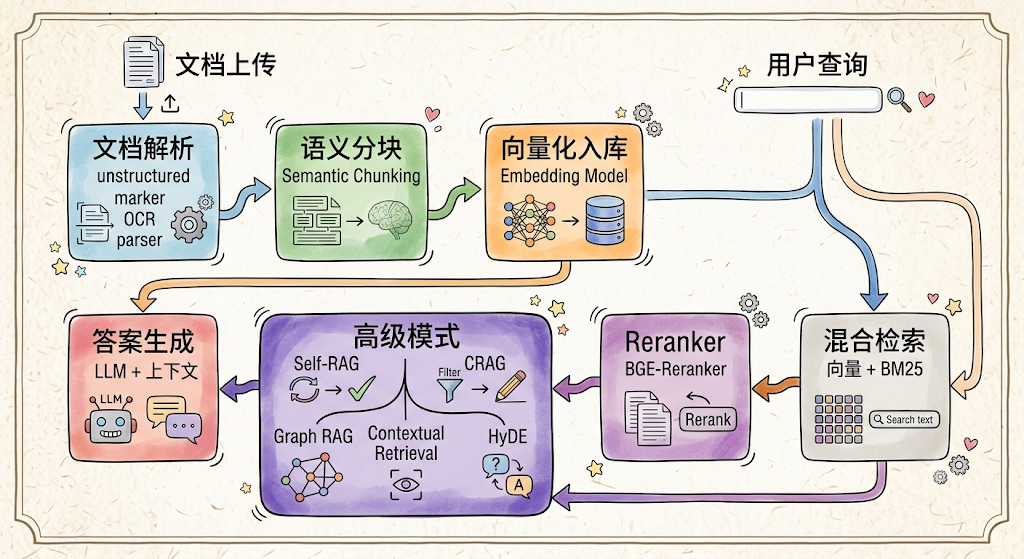
文档解析层引入 unstructured 库 + marker(PDF 转 Markdown)+ 自研的表格提取器,提升复杂文档(扫描件、多栏 PDF、嵌套表格)的解析质量。分块策略从固定大小升级为语义分块(Semantic Chunking),使用 nltk 或 spacy 做句子边界检测,结合嵌入相似度判断语义断点。检索策略实现混合检索(向量 + BM25)+ BGE-Reranker 重排序的双通道方案。增加高级 RAG 模式:Self-RAG(模型自判断是否需要检索)、Corrective RAG(检索后自评估相关性,不相关则重新检索)、Graph RAG(基于知识图谱的结构化检索)。
评估体系引入 RAGAS 框架,自动化评估检索召回率、答案忠实度、答案相关性等核心指标,建立 RAG 质量的持续改进闭环。
RAG 引擎处理流水线:
5.4.4 模型网关(Model Gateway)
在 Dify 的模型插件体系基础上构建统一模型网关。核心设计是 BaseLLMProvider ABC + Registry 模式,每个 LLM 提供商(OpenAI、Anthropic、通义千问、DeepSeek、本地 Ollama 等)实现统一接口。
关键能力包括:Fallback Chain(主模型不可用时自动降级到备选模型)、Circuit Breaker(使用 pybreaker 库,连续失败时熔断保护)、Token Budget Manager(按租户/应用/用户三个维度管控 Token 消耗)、流式输出标准化(将不同 Provider 的 SSE 格式统一为平台标准格式)。
在此基础上集成 LiteLLM 1.55+ 作为一个后端实现,利用其已有的 100+ Provider 适配能力快速覆盖长尾模型。
5.4.5 插件运行时(Plugin Runtime)
Dify 的插件通过独立 Daemon 进程运行。二次开发时优化为两种运行模式:内置插件直接在主进程内加载(通过 importlib.metadata entry points 自动发现),降低调用延迟;第三方插件运行在隔离沙盒中(使用 Docker container 或 nsjail),通过 gRPC 与主进程通信,确保安全隔离。
引入 pluggy 1.5.x 作为插件钩子系统,定义标准的 Hook Spec(如 before_workflow_run、after_node_execute、on_error 等),允许插件在工作流生命周期的关键节点注入自定义逻辑。
5.5 平台服务层
这一层面向平台运营管理,Dify 开源版在这部分相对薄弱,是二次开发的重点增量。
用户与权限:在 Dify 基础 RBAC 上扩展为 ABAC(基于属性的访问控制),支持细粒度的资源级权限(某用户只能访问自己创建的工作流)。集成企业 SSO(OIDC/SAML 2.0),支持 LDAP 目录同步。
多租户:采用行级安全(PostgreSQL Row-Level Security)实现数据隔离,免费/专业版租户共享数据库通过 RLS 策略隔离,企业版租户支持独立数据库。向量数据库通过 tenant_id metadata 过滤实现租户隔离。
审计与合规:全量操作审计日志(谁在什么时间修改了什么工作流、调用了什么模型、消耗了多少 Token),支持日志导出和合规报告生成。
计费系统:基于 Token 消耗量 + API 调用次数 + 存储用量的三维计费模型,支持预付费额度包和后付费账单,通过 Redis 实现实时用量计量。
5.6 应用编排层
这是用户直接交互的层面,核心是可视化工作流编辑器。
编辑器增强:在 React Flow 基础上引入 AntV X6 3.x 的能力——内置撤销/重做、框选对齐、小地图导航。增加"调试模式"——允许用户在画布上选中任意节点设置断点,单步执行并观察每个节点的输入/输出。增加"子流程折叠"——将一组节点打包为子流程,在画布上显示为单个可展开的节点。
应用模板市场:建立模板生态,预置 20+ 行业场景模板(客服机器人、文档问答、数据分析助手、代码审查等),支持一键部署和参数调整。
协作编辑:基于 Yjs(CRDT 库)+ WebSocket 实现多人实时协作编辑同一个工作流,支持光标感知和操作锁定。
5.7 接入层
接入层统一管理所有外部通信。REST API 遵循 OpenAPI 3.1 规范,自动生成 SDK(Python/TypeScript/Go)。SSE(Server-Sent Events)用于工作流执行过程的实时状态推送和 LLM 流式输出。WebSocket 用于协作编辑和长时间运行的双向通信。
关键新增:构建 MCP Server(Model Context Protocol),让平台本身成为一个 MCP 工具提供者,可被 Claude Desktop、Cursor 等 MCP 客户端直接调用。这使得基于我们平台构建的 AI 应用能够被更广泛的 AI 工具生态无缝集成。
六、整体 SaaS 架构设计
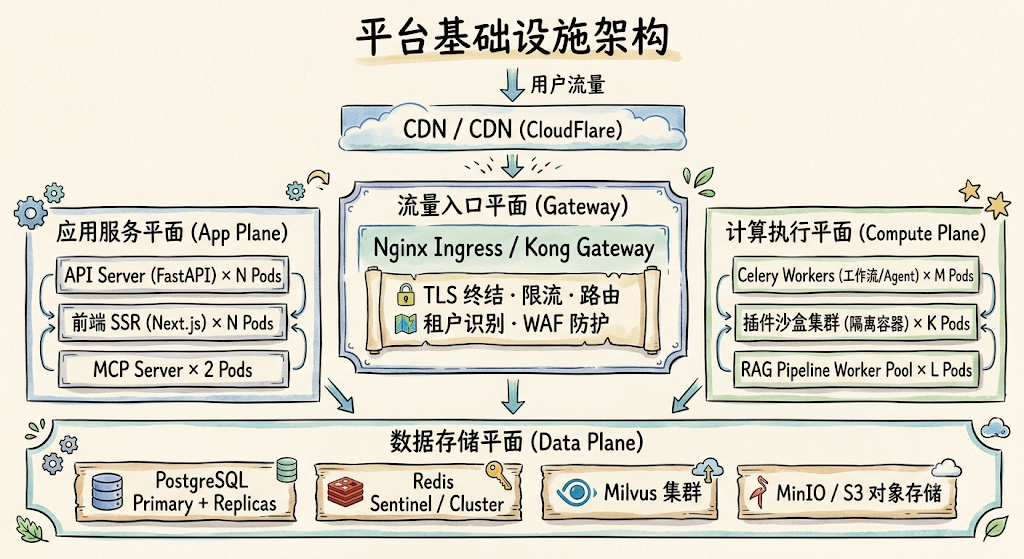
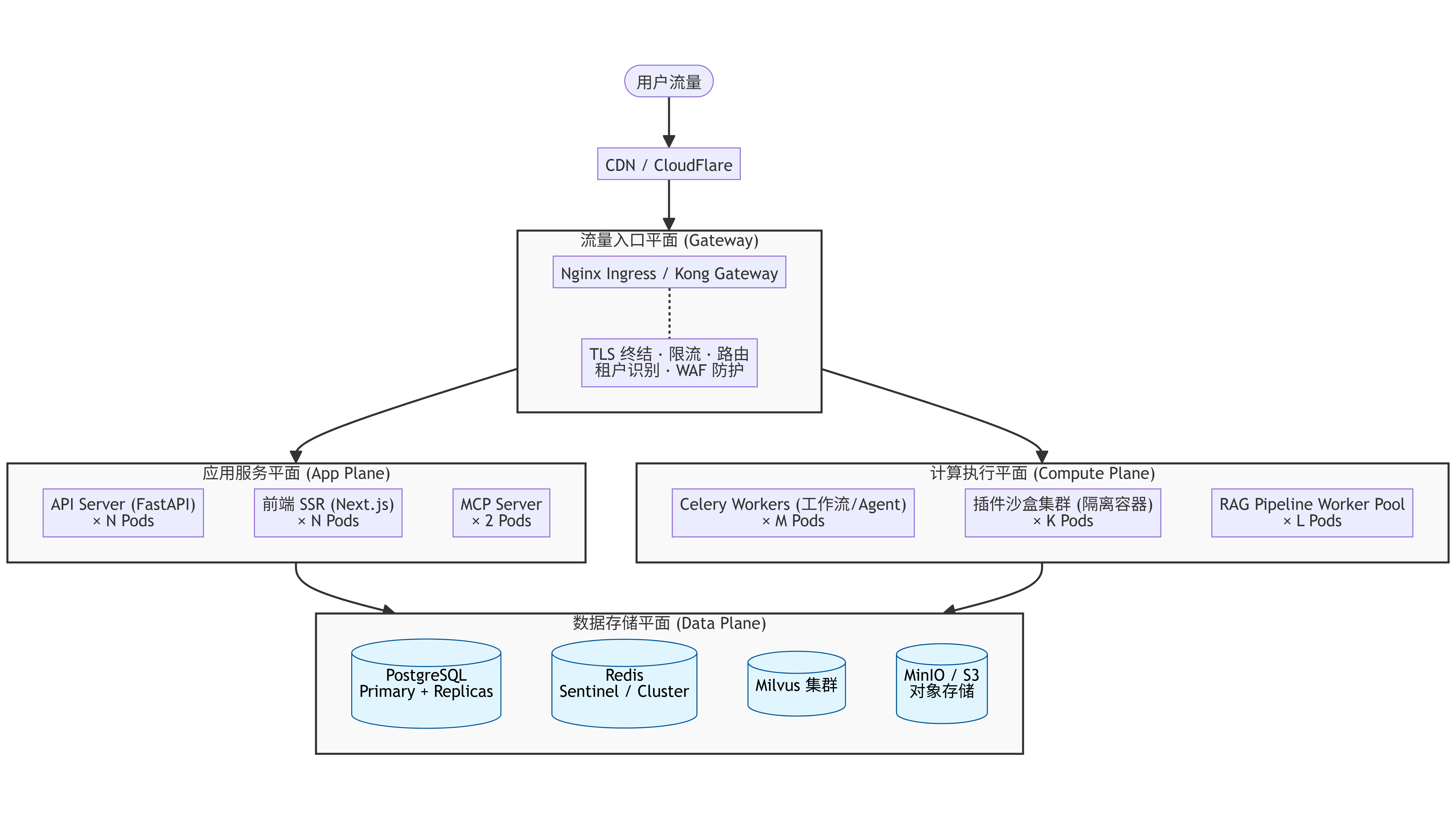
6.1 SaaS 部署拓扑总览
平台以 Kubernetes 为底座,划分为四个功能平面(Plane):流量入口平面、应用服务平面、计算执行平面、数据存储平面。各平面独立扩缩容,通过内部 Service Mesh 通信。
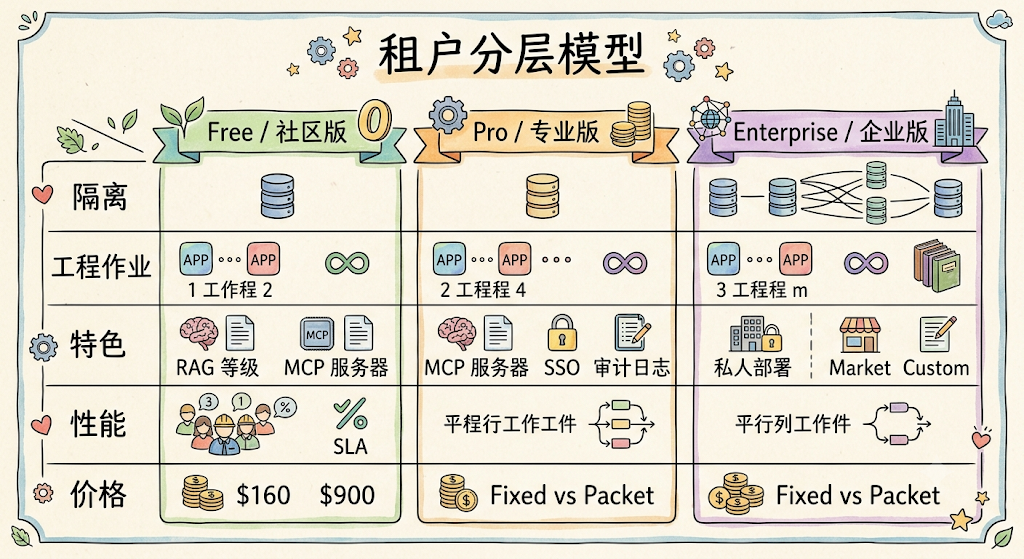
6.2 多租户分层模型
SaaS 平台设计三档租户套餐,每档对应不同的资源隔离等级、功能范围和计费方式。
6.3 请求流量分层路由
所有外部请求通过 API Gateway 统一接入,Gateway 根据请求中的租户标识(域名前缀 / API Key / JWT claim)将流量路由到对应的处理链路。
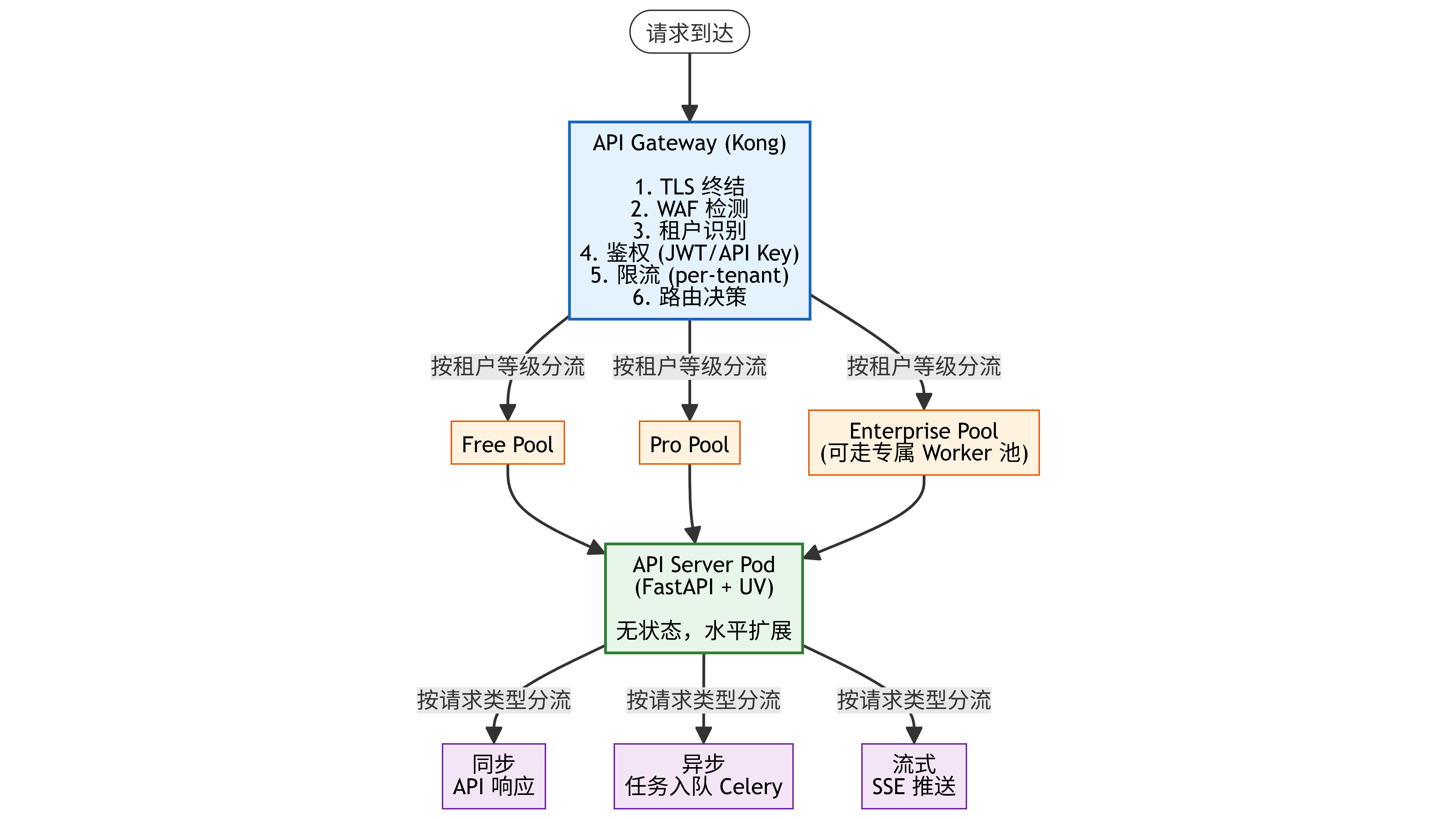
租户识别策略:支持三种方式——自定义域名(enterprise.acme.com → 映射到 tenant_id)、子域名(acme.platform.com → 映射到 tenant_id)、以及 API Key 前缀(sk-pro-xxx → Pro 租户,sk-ent-xxx → Enterprise 租户)。Gateway 层将 tenant_id 注入请求 Header(X-Tenant-ID),后续所有中间件和服务据此做隔离和路由。
限流策略:基于 Redis 的滑动窗口限流,按租户 + 端点两个维度控制。Free 租户限制 60 次/分钟(全局)、LLM 调用 10 次/分钟;Pro 租户 300 次/分钟、LLM 调用 60 次/分钟;Enterprise 租户可自定义上限,默认 1000 次/分钟。
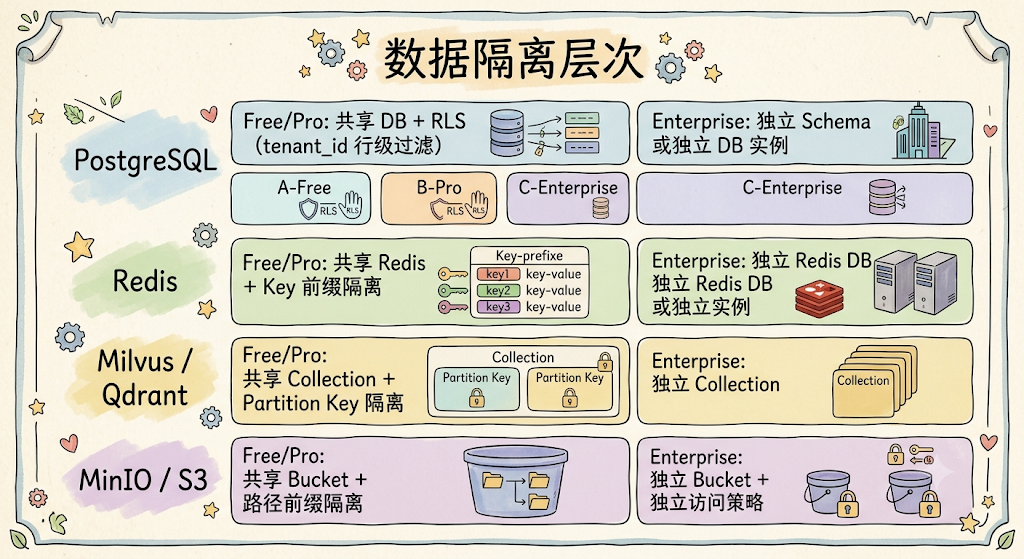
6.4 数据隔离架构
数据隔离是 SaaS 架构的核心安全问题,采用分层隔离策略。
PostgreSQL 隔离:Free 和 Pro 租户共享同一 PostgreSQL 实例,通过 Row-Level Security(RLS)策略实现行级隔离。每个业务表都包含 tenant_id 列,PostgreSQL 自动根据当前会话的 app.current_tenant 变量过滤数据。Enterprise 租户支持两种升级路径——独立 Schema(同一实例,DDL 隔离)或独立数据库实例(完全物理隔离)。
-- RLS 策略示例
ALTER TABLE workflows ENABLE ROW LEVEL SECURITY;
CREATE POLICY tenant_isolation ON workflows
USING (tenant_id = current_setting('app.current_tenant')::uuid);
-- 每次连接时设置当前租户
SET app.current_tenant = '550e8400-e29b-41d4-a716-446655440000';
Redis 隔离:Free 和 Pro 租户共享 Redis,通过 Key 前缀隔离(tenant:{tenant_id}:cache:*)。Enterprise 租户分配独立的 Redis DB 编号(db0-db15),或使用独立 Redis 实例。
向量数据库隔离:Milvus 通过 Collection 级别的 Partition 隔离(每个租户一个 Partition Key),Pro 和 Enterprise 租户可选择独立 Collection。Qdrant 通过 tenant_id payload filter + 独立 Collection(Enterprise)实现。
对象存储隔离:MinIO 通过 Bucket 前缀隔离(/{tenant_id}/documents/*),Enterprise 租户使用独立 Bucket + 独立的访问策略。
6.5 弹性伸缩策略
各平面根据负载特征采用不同的伸缩策略,通过 Kubernetes HPA(Horizontal Pod Autoscaler)和 VPA(Vertical Pod Autoscaler)实现自动化。
API Server(应用服务平面):基于 CPU 利用率(>70%)和请求延迟 P95(>500ms)触发水平扩展。无状态设计,Pod 数量可线性增长。最小 2 副本(高可用),最大按集群容量动态扩展。
Celery Worker(计算执行平面):基于 Celery 队列深度(队列中等待任务数 > 阈值)触发扩展。工作流 Worker 和 LLM 调用 Worker 使用独立的 Worker Pool,支持分别扩缩容。工作流 Worker 按 CPU 扩展,LLM Worker 按网络 I/O 和队列深度扩展。Enterprise 租户的专属 Worker 池独立于共享池,保证资源不被其他租户抢占。
RAG Pipeline Worker:按 GPU 节点(如有本地 Embedding 模型)或 CPU 节点扩展,基于向量索引构建队列深度触发。
# HPA 示例:API Server 自动扩缩
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: api-server-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: api-server
minReplicas: 2
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Pods
pods:
metric:
name: http_request_duration_p95_ms
target:
type: AverageValue
averageValue: "500"
# HPA 示例:Celery Worker 按队列深度扩缩
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: celery-worker-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: celery-worker
minReplicas: 2
maxReplicas: 50
metrics:
- type: External
external:
metric:
name: celery_queue_length
selector:
matchLabels:
queue: workflow_execution
target:
type: AverageValue
averageValue: "10"
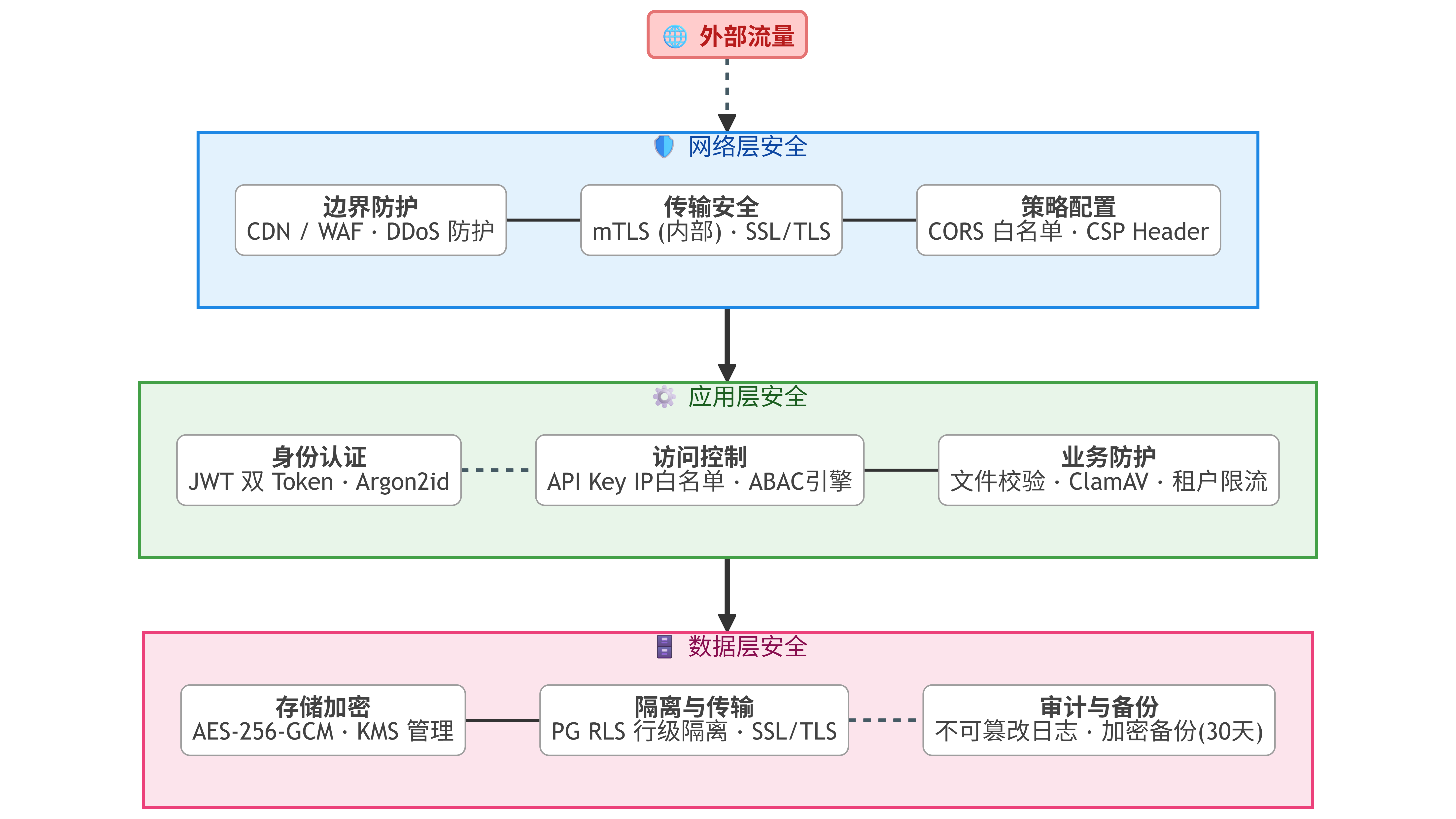
6.6 安全架构
SaaS 安全设计覆盖网络层、应用层、数据层三个维度。
网络层安全:所有外部流量经 CDN(CloudFlare)和 WAF(Web Application Firewall)过滤,防御 DDoS、SQL 注入、XSS 等攻击。内部服务间通信通过 Kubernetes Service Mesh(Istio 或 Linkerd)实现 mTLS 加密。API Gateway 配置 CORS 白名单和 CSP(Content Security Policy)Header。
应用层安全:JWT 双 Token 机制(Access Token 15 分钟过期 + Refresh Token 7 天过期),支持强制下线。API Key 支持作用域限制(只读/读写/管理员)和 IP 白名单。所有用户密码使用 Argon2id 哈希存储。文件上传严格校验类型和大小(文档最大 50MB,图片最大 10MB),上传后进行病毒扫描(ClamAV)。
数据层安全:敏感字段(API Key、模型密钥、SSO 配置)使用 AES-256-GCM 加密存储,密钥由 KMS(Key Management Service)管理。数据库连接使用 SSL/TLS 加密。备份数据加密存储,保留 30 天。所有数据操作记录到审计日志(不可篡改,写入独立的审计日志表或外部日志系统)。
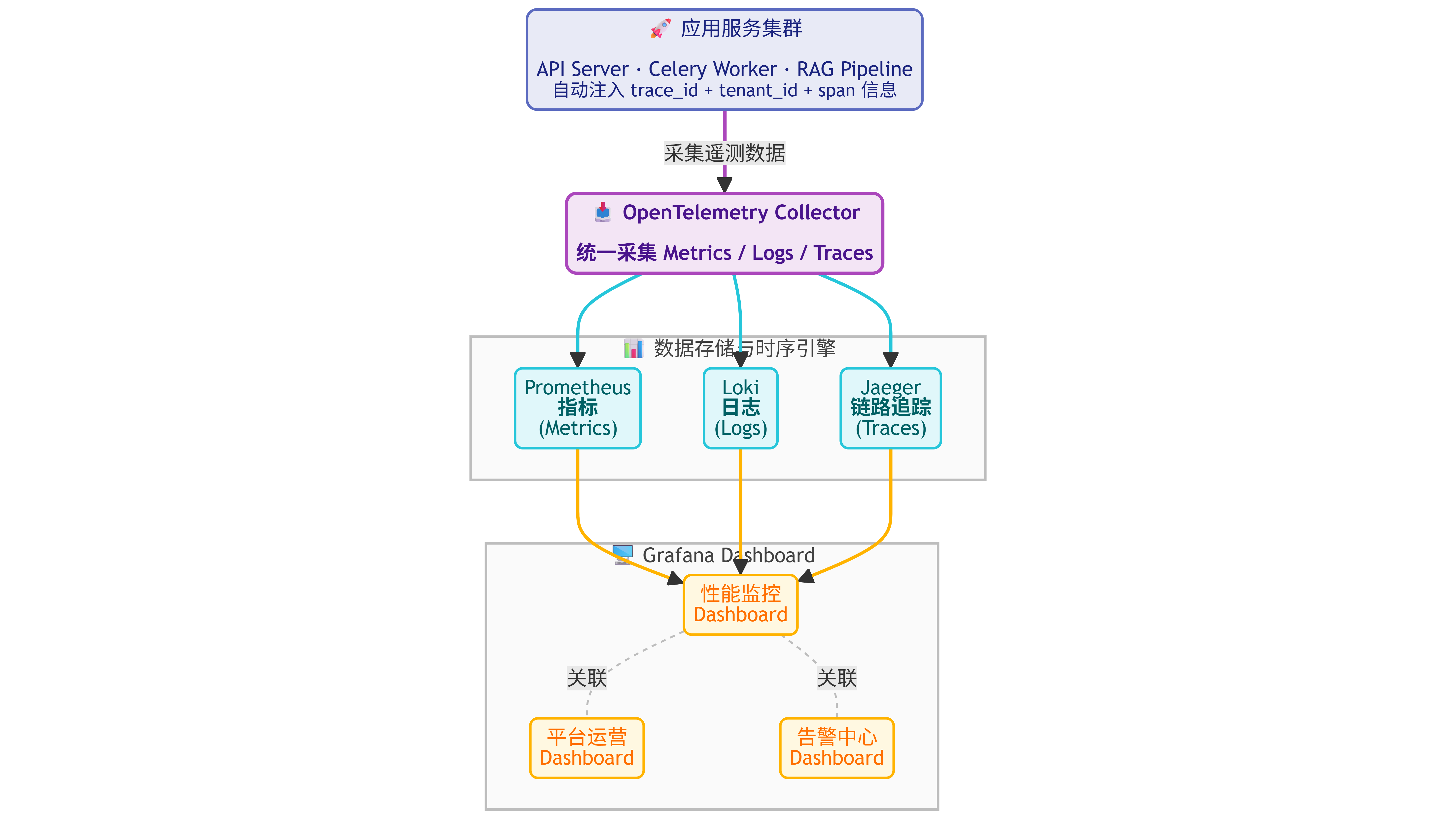
6.7 可观测性与运维体系
SaaS 平台的可观测性覆盖三个维度:Metrics(指标)、Logging(日志)、Tracing(链路追踪)。
Metrics:通过 Prometheus 采集,Grafana 可视化。核心监控指标包括——平台级指标(DAU/MAU、注册转化率、各套餐租户数、整体收入);性能指标(API P50/P95/P99 延迟、工作流平均执行时间、LLM 首 Token 延迟);资源指标(CPU/内存利用率、PostgreSQL 连接数、Redis 内存使用率、Celery 队列深度);业务指标(工作流执行成功/失败率、RAG 检索准确率、模型调用成功率、Token 消耗趋势)。
Logging:使用 Loki(轻量级)或 ELK Stack(重量级)聚合日志。日志分级:应用日志(Python logging,JSON 结构化输出)、访问日志(Nginx/Gateway access log)、审计日志(独立存储,不可删除)。所有日志自动注入 trace_id、tenant_id、user_id 三个关联字段,支持跨维度检索。
Tracing:OpenTelemetry SDK 自动注入,覆盖 HTTP 请求 → API 处理 → Celery 任务 → LLM 调用 → 向量检索 全链路。使用 Jaeger 或 Grafana Tempo 存储和查询 Trace。支持按 tenant_id 过滤 Trace,便于定位特定租户的性能瓶颈。
告警规则:基于 Prometheus AlertManager 配置分级告警。P0 级(立即通知):API 服务不可用、数据库连接池耗尽、工作流执行全量失败;P1 级(15 分钟内响应):P95 延迟 > 2s、Celery 队列堆积 > 100、单租户错误率 > 10%;P2 级(1 小时内关注):磁盘使用率 > 80%、Redis 内存使用率 > 75%、SSL 证书 30 天内过期。告警通道支持钉钉/飞书/企微 Webhook + PagerDuty + 短信。
6.8 灾备与容灾设计
数据备份:PostgreSQL 采用持续归档(WAL Archive)+ 每日全量备份(pg_dump),备份加密存储到独立的 S3 Bucket,保留 30 天。Redis 开启 AOF 持久化 + 每小时 RDB 快照。Milvus/Qdrant 每日全量快照。所有备份定期做恢复演练(每月一次),验证 RPO(Recovery Point Objective)< 1 小时。
高可用部署:PostgreSQL 采用一主两从流复制 + 自动故障切换(Patroni),RTO(Recovery Time Objective)< 30 秒。Redis 采用 Sentinel 模式(一主两从三哨兵)或 Cluster 模式。API Server 最少 2 副本跨可用区部署。Celery Worker 最少 2 副本,任务幂等设计保证重试安全。
多区域部署(远期规划):Phase 1-3 单区域部署满足大部分场景。Phase 4 及之后可规划多区域部署——数据库采用跨区域复制(PostgreSQL Logical Replication),对象存储启用跨区域复制(S3 Cross-Region Replication),DNS 使用 GeoDNS 将用户路由到最近区域。
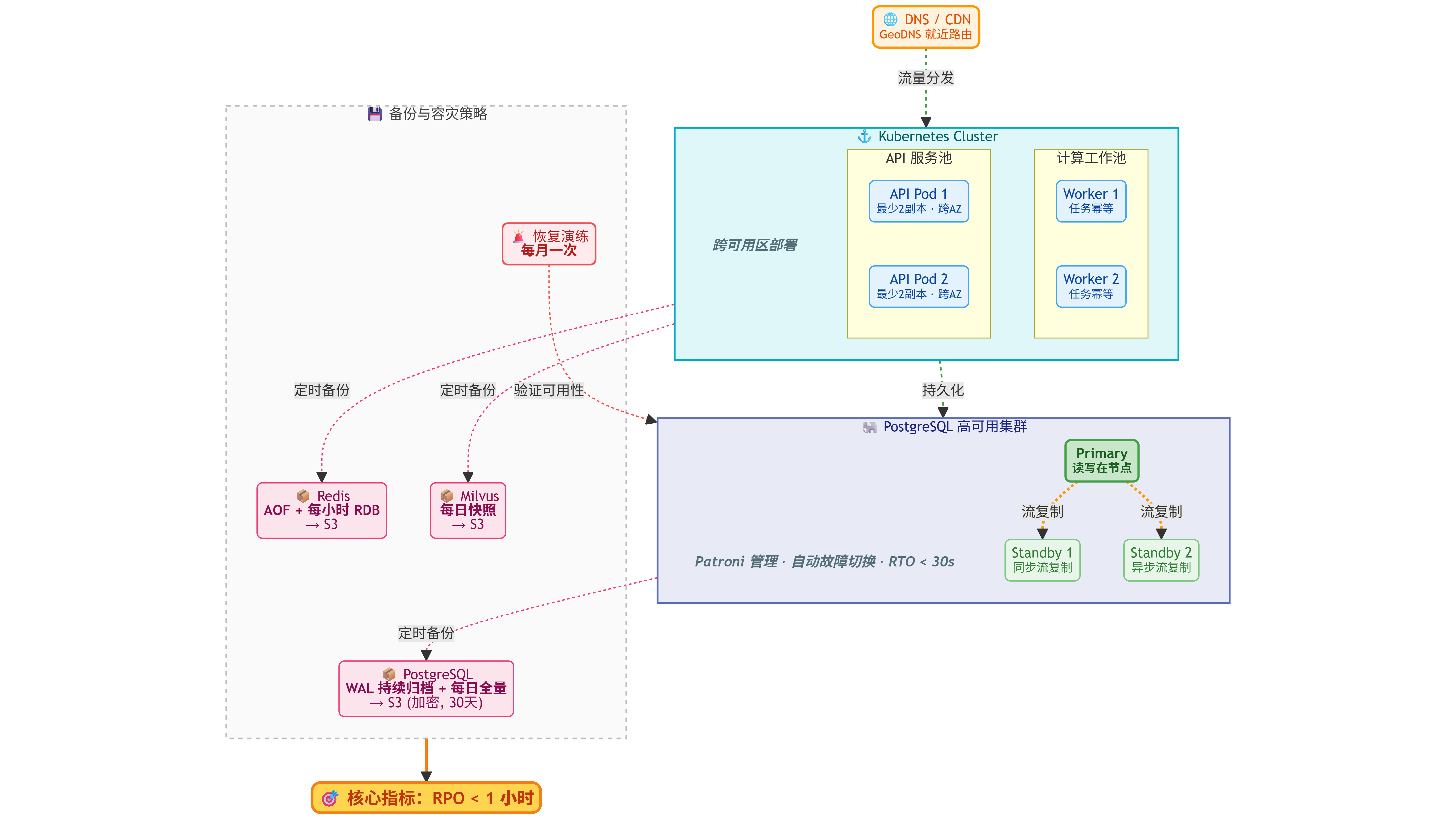
6.9 租户生命周期管理
租户从注册到注销的全生命周期由 Tenant Lifecycle Manager 统一管理。
注册与初始化(Provisioning):用户注册后,系统自动创建租户记录(tenant_id)、初始化默认配置(默认模型、默认知识库配额)、创建 Free 套餐的 RLS 策略、发送欢迎邮件。Enterprise 租户的 Provisioning 还包括创建独立数据库 Schema、独立 Redis DB、独立向量 Collection,以及初始化 SSO 配置。
套餐升降级(Upgrade / Downgrade):升级时即时生效——解锁新功能、提升限额、必要时触发数据迁移(如 Free → Enterprise 需要将数据从共享 DB 迁移到独立 Schema)。降级在计费周期结束后生效——保留数据但冻结超额资源(超额的工作流变为只读),给用户 30 天缓冲期。
停用与注销(Deprovisioning):租户取消订阅后进入 90 天"冷冻期"——数据保留但不可访问,用户可随时恢复。冷冻期过后执行数据清理:删除 PostgreSQL 数据、Redis 缓存、向量索引、对象存储文件。清理操作使用异步任务队列执行,避免阻塞正常业务。所有清理操作记录到审计日志。
6.10 SaaS 计费引擎设计
计费引擎基于 Redis 实现实时用量计量,每日凌晨生成账单快照写入 PostgreSQL。
计量维度:Token 消耗量(按 LLM Provider 分别计量 input/output tokens)、API 调用次数(按端点类型区分:对话 API / 工作流 API / 知识库 API)、存储用量(知识库文档数 + 向量数 + 对象存储字节数)、工作流执行次数(按节点数加权:10 节点以内 ×1,10-50 节点 ×2,50+ 节点 ×5)。
计费流程:每次 LLM 调用 / 工作流执行 / API 调用完成后,Worker 通过 Redis Pipeline 原子递增对应的计量 Key(metering:{tenant_id}:{date}:{dimension})。Redis Key 设置 48 小时过期(防止未结算数据永久驻留)。每日凌晨 Billing Scheduler(Celery Beat 任务)扫描所有租户的计量 Key,按定价策略计算费用,生成账单写入 PostgreSQL。
# 计费计量核心代码
import redis.asyncio as redis
class MeteringService:
"""基于 Redis 的实时用量计量"""
def __init__(self, redis_client: redis.Redis):
self.redis = redis_client
async def record_usage(
self, tenant_id: str, dimension: str, amount: int
):
"""记录一次用量(原子操作)"""
from datetime import date
today = date.today().isoformat()
key = f"metering:{tenant_id}:{today}:{dimension}"
pipe = self.redis.pipeline()
pipe.incrby(key, amount)
pipe.expire(key, 172800) # 48 小时过期
await pipe.execute()
async def get_usage(
self, tenant_id: str, start_date: str, end_date: str
) -> dict:
"""查询指定时间段的用量"""
dimensions = [
"tokens_input", "tokens_output",
"api_calls_chat", "api_calls_workflow",
"storage_docs", "storage_vectors", "storage_bytes",
"workflow_executions",
]
result = {}
for dim in dimensions:
total = 0
d = start_date
while d <= end_date:
key = f"metering:{tenant_id}:{d}:{dim}"
val = await self.redis.get(key)
total += int(val) if val else 0
result[dim] = total
return result
# 定价策略
PRICING = {
"free": {
"tokens_input": 0, # 免费赠送 100K tokens/月
"tokens_output": 0,
"api_calls_chat": 0, # 免费 1000 次/月
"api_calls_workflow": 0, # 免费 100 次/月
},
"pro": {
"tokens_input": 0.0001, # ¥0.0001 / token
"tokens_output": 0.0002, # ¥0.0002 / token
"api_calls_chat": 0.01, # ¥0.01 / 次
"api_calls_workflow": 0.1,# ¥0.1 / 次
},
"enterprise": {
# 自定义报价,通常为 Pro 的 60-80%
"tokens_input": 0.00007,
"tokens_output": 0.00014,
"api_calls_chat": 0.007,
"api_calls_workflow": 0.07,
},
}
七、Python 后端代码架构设计
7.1 项目包结构
二次开发的 Python 后端采用独立 package 组织自研代码,通过组合方式与 Dify 原有代码集成,而非直接修改上游源码。
ai-workflow-platform/
├── dify/ # Dify 上游代码(git submodule)
│ ├── api/ # Dify 原始 Flask API
│ ├── web/ # Dify 原始 Next.js 前端
│ └── ...
├── src/ # 自研代码(独立 package)
│ ├── core/ # 核心引擎层
│ │ ├── workflow/ # 工作流引擎
│ │ │ ├── engine.py # DAG 执行引擎
│ │ │ ├── state_machine.py # transitions 状态机
│ │ │ ├── node_base.py # 节点基类 ABC
│ │ │ ├── nodes/ # 内置节点实现
│ │ │ │ ├── llm_call.py
│ │ │ │ ├── knowledge_retrieval.py
│ │ │ │ ├── if_else.py
│ │ │ │ ├── for_each.py
│ │ │ │ ├── code_node.py
│ │ │ │ └── ...
│ │ │ └── checkpoint.py # 断点续跑持久化
│ │ ├── agent/ # Agent 引擎
│ │ │ ├── protocol.py # AgentProtocol ABC
│ │ │ ├── orchestrator.py # Orchestrator-Worker 模式
│ │ │ ├── debate.py # Debate 模式
│ │ │ ├── pipeline.py # Pipeline 模式
│ │ │ ├── memory.py # MemoryManager
│ │ │ └── tool_reasoning.py # 工具选择推理
│ │ ├── rag/ # RAG 引擎
│ │ │ ├── parser/ # 文档解析器
│ │ │ │ ├── base.py # DocumentParser ABC
│ │ │ │ ├── pdf_parser.py # PDF 解析(marker + OCR)
│ │ │ │ ├── docx_parser.py
│ │ │ │ └── web_parser.py
│ │ │ ├── chunker/ # 分块策略
│ │ │ │ ├── base.py # Chunker ABC
│ │ │ │ ├── semantic.py # 语义分块
│ │ │ │ └── recursive.py # 递归字符分块
│ │ │ ├── retriever/ # 检索器
│ │ │ │ ├── hybrid.py # 混合检索(向量+BM25)
│ │ │ │ └── reranker.py # BGE-Reranker
│ │ │ ├── advanced/ # 高级 RAG 模式
│ │ │ │ ├── self_rag.py
│ │ │ │ ├── corrective_rag.py
│ │ │ │ └── graph_rag.py
│ │ │ └── evaluator.py # RAGAS 评估
│ │ └── model_gateway/ # 模型网关
│ │ ├── provider.py # BaseLLMProvider ABC
│ │ ├── registry.py # Provider Registry
│ │ ├── fallback.py # Fallback Chain
│ │ ├── circuit_breaker.py # 熔断器
│ │ ├── budget.py # Token Budget Manager
│ │ ├── stream_normalizer.py# 流式输出标准化
│ │ └── providers/ # 各 Provider 实现
│ │ ├── openai_provider.py
│ │ ├── anthropic_provider.py
│ │ ├── qwen_provider.py
│ │ ├── deepseek_provider.py
│ │ ├── ollama_provider.py
│ │ └── litellm_provider.py # LiteLLM 适配层
│ ├── platform/ # 平台服务层
│ │ ├── auth/ # 认证与权限
│ │ │ ├── abac.py # ABAC 权限引擎
│ │ │ ├── sso.py # SSO 集成(OIDC/SAML)
│ │ │ └── ldap_sync.py # LDAP 目录同步
│ │ ├── tenant/ # 多租户
│ │ │ ├── rls.py # Row-Level Security
│ │ │ └── isolation.py # 租户隔离策略
│ │ ├── billing/ # 计费
│ │ │ ├── metering.py # Redis 实时计量
│ │ │ ├── pricing.py # 定价策略
│ │ │ └── invoice.py # 账单生成
│ │ └── audit/ # 审计
│ │ ├── logger.py # 审计日志记录器
│ │ └── report.py # 合规报告
│ ├── plugins/ # 插件运行时
│ │ ├── runtime.py # 插件加载与管理
│ │ ├── hooks.py # pluggy Hook Spec 定义
│ │ ├── sandbox.py # 沙盒执行环境
│ │ └── builtin/ # 内置插件
│ │ ├── tools/ # 工具插件
│ │ └── ...
│ ├── api/ # 新增 API 层(FastAPI)
│ │ ├── main.py # FastAPI 应用入口
│ │ ├── middleware/ # 中间件
│ │ │ ├── auth.py # JWT/OAuth 中间件
│ │ │ ├── tenant.py # 租户识别中间件
│ │ │ └── rate_limit.py # 限流中间件
│ │ ├── routes/ # 路由
│ │ │ ├── workflow.py # 工作流 CRUD
│ │ │ ├── execution.py # 执行与状态推送
│ │ │ ├── knowledge.py # 知识库管理
│ │ │ ├── model.py # 模型管理
│ │ │ └── plugin.py # 插件管理
│ │ └── schemas/ # Pydantic 数据模型
│ ├── mcp/ # MCP Server
│ │ ├── server.py # MCP 协议实现
│ │ └── tools.py # 暴露为 MCP 工具的能力
│ └── common/ # 公共工具
│ ├── config.py # 配置管理
│ ├── exceptions.py # 统一异常
│ ├── logging.py # 日志配置
│ └── telemetry.py # OpenTelemetry 集成
├── tests/ # 测试
│ ├── unit/ # 单元测试
│ ├── integration/ # 集成测试
│ └── e2e/ # 端到端测试
├── migrations/ # Alembic 数据库迁移
├── docker/ # Docker 相关
│ ├── Dockerfile.api
│ ├── Dockerfile.worker
│ └── docker-compose.yml # 精简部署(5-6 容器)
├── helm/ # Kubernetes Helm Charts
├── pyproject.toml # Python 项目配置
└── Makefile # 常用命令
7.2 核心引擎层关键类设计
工作流引擎核心类
from abc import ABC, abstractmethod
from enum import Enum
from transitions import Machine
from dataclasses import dataclass, field
from typing import Any, Optional
import asyncio
class NodeState(str, Enum):
PENDING = "pending"
RUNNING = "running"
SUCCESS = "success"
FAILED = "failed"
SKIPPED = "skipped"
RETRYING = "retrying"
class NodeBase(ABC):
"""所有工作流节点的基类"""
def __init__(self, node_id: str, config: dict):
self.node_id = node_id
self.config = config
self.state = NodeState.PENDING
self._init_state_machine()
def _init_state_machine(self):
self.machine = Machine(
model=self,
states=[s.value for s in NodeState],
transitions=[
{"trigger": "schedule", "source": "pending", "dest": "running"},
{"trigger": "succeed", "source": "running", "dest": "success"},
{"trigger": "fail", "source": "running", "dest": "failed"},
{"trigger": "skip", "source": "pending", "dest": "skipped"},
{"trigger": "retry", "source": "failed", "dest": "retrying"},
{"trigger": "reschedule", "source": "retrying", "dest": "running"},
],
initial="pending",
)
@abstractmethod
async def execute(self, context: "ExecutionContext") -> dict:
"""节点执行逻辑,子类必须实现"""
...
async def on_enter_running(self):
"""进入 running 状态时的回调"""
await self._save_checkpoint()
async def on_enter_failed(self):
"""进入 failed 状态时的回调"""
await self._save_checkpoint()
async def _save_checkpoint(self):
"""将当前节点状态持久化到 PostgreSQL,支持断点续跑"""
...
@dataclass
class ExecutionContext:
"""工作流执行上下文"""
workflow_id: str
execution_id: str
tenant_id: str
variables: dict = field(default_factory=dict)
node_outputs: dict = field(default_factory=dict)
trace_id: Optional[str] = None
class WorkflowEngine:
"""DAG 工作流执行引擎"""
def __init__(self, model_gateway, plugin_runtime, checkpoint_store):
self.model_gateway = model_gateway
self.plugin_runtime = plugin_runtime
self.checkpoint_store = checkpoint_store
async def execute(self, workflow_graph: dict, context: ExecutionContext):
"""按拓扑排序执行 DAG"""
sorted_nodes = self._topological_sort(workflow_graph)
for node in sorted_nodes:
# 检查是否有断点可恢复
checkpoint = await self.checkpoint_store.get(
context.execution_id, node.node_id
)
if checkpoint and checkpoint.state == NodeState.SUCCESS:
continue # 跳过已成功执行的节点
await node.schedule()
try:
result = await node.execute(context)
context.node_outputs[node.node_id] = result
await node.succeed()
except Exception as e:
await node.fail()
if node.config.get("max_retries", 0) > 0:
await self._retry_with_backoff(node, context)
else:
raise
模型网关核心类
from abc import ABC, abstractmethod
from dataclasses import dataclass
from typing import AsyncIterator, Optional
import pybreaker
@dataclass
class ChatMessage:
role: str
content: str
@dataclass
class LLMResponse:
content: str
usage: dict # {"prompt_tokens": int, "completion_tokens": int}
model: str
finish_reason: str
class BaseLLMProvider(ABC):
"""所有 LLM Provider 的抽象基类"""
@abstractmethod
async def chat(
self, messages: list[ChatMessage], **kwargs
) -> LLMResponse:
...
@abstractmethod
async def chat_stream(
self, messages: list[ChatMessage], **kwargs
) -> AsyncIterator[str]:
...
@abstractmethod
async def embedding(self, texts: list[str]) -> list[list[float]]:
...
@property
@abstractmethod
def provider_name(self) -> str:
...
class ProviderRegistry:
"""Provider 注册表"""
_providers: dict[str, BaseLLMProvider] = {}
_fallback_chains: dict[str, list[str]] = {}
@classmethod
def register(cls, name: str, provider: BaseLLMProvider):
cls._providers[name] = provider
@classmethod
def set_fallback_chain(cls, primary: str, fallbacks: list[str]):
"""设置模型降级链:主模型 → 备选1 → 备选2"""
cls._fallback_chains[primary] = fallbacks
@classmethod
async def get_with_fallback(cls, name: str) -> BaseLLMProvider:
"""获取 Provider,支持自动降级"""
if name in cls._providers:
return cls._providers[name]
for fallback in cls._fallback_chains.get(name, []):
if fallback in cls._providers:
return cls._providers[fallback]
raise ProviderUnavailableError(f"No available provider for: {name}")
class CircuitBreakerMixin:
"""熔断器混入,连续失败 5 次后熔断 60 秒"""
breaker = pybreaker.CircuitBreaker(
fail_max=5, reset_timeout=60
)
RAG 引擎核心类
from abc import ABC, abstractmethod
from dataclasses import dataclass
@dataclass
class Document:
id: str
content: str
metadata: dict
@dataclass
class Chunk:
id: str
document_id: str
content: str
embedding: Optional[list[float]] = None
metadata: dict = field(default_factory=dict)
class DocumentParser(ABC):
"""文档解析器基类"""
@abstractmethod
async def parse(self, file_path: str) -> Document:
...
class Chunker(ABC):
"""分块策略基类"""
@abstractmethod
def chunk(self, document: Document, config: dict) -> list[Chunk]:
...
class SemanticChunker(Chunker):
"""语义分块:基于句子边界 + 嵌入相似度判断语义断点"""
def __init__(self, embedding_model, similarity_threshold=0.5):
self.embedding_model = embedding_model
self.similarity_threshold = similarity_threshold
def chunk(self, document: Document, config: dict) -> list[Chunk]:
sentences = self._split_sentences(document.content)
embeddings = self.embedding_model.embed(sentences)
chunks = []
current_chunk = [sentences[0]]
for i in range(1, len(sentences)):
sim = self._cosine_similarity(embeddings[i-1], embeddings[i])
if sim < self.similarity_threshold:
chunks.append(self._make_chunk(current_chunk, document))
current_chunk = []
current_chunk.append(sentences[i])
if current_chunk:
chunks.append(self._make_chunk(current_chunk, document))
return chunks
class VectorStoreProvider(ABC):
"""向量数据库基类"""
@abstractmethod
async def upsert(self, chunks: list[Chunk], tenant_id: str): ...
@abstractmethod
async def search(self, query_embedding: list[float],
top_k: int, tenant_id: str,
filters: dict = None) -> list[Chunk]: ...
class HybridRetriever:
"""混合检索器:向量检索 + BM25 关键词检索 + Reranker 重排序"""
def __init__(self, vector_store, bm25_index, reranker):
self.vector_store = vector_store
self.bm25_index = bm25_index
self.reranker = reranker
async def retrieve(self, query: str, top_k: int = 10,
tenant_id: str = None) -> list[Chunk]:
# 1. 向量检索
query_embedding = await self._embed(query)
vector_results = await self.vector_store.search(
query_embedding, top_k=top_k*2, tenant_id=tenant_id
)
# 2. BM25 关键词检索
bm25_results = self.bm25_index.search(query, top_k=top_k*2)
# 3. 融合去重(RRF - Reciprocal Rank Fusion)
merged = self._rrf_merge(vector_results, bm25_results)
# 4. Reranker 重排序
reranked = await self.reranker.rerank(query, merged[:top_k])
return reranked
7.3 Flask → FastAPI 渐进式迁移策略
Dify 原有后端基于 Flask(WSGI),而 FastAPI(ASGI)在异步性能、类型安全和开发体验上明显优于 Flask。全面替换风险高,推荐渐进式迁移:
第一阶段(第 1 月):新增一个 FastAPI 应用实例,通过 ASGI 中间件(如 asgiref)将 FastAPI 挂载到 Dify 的 Flask 应用旁,新模块一律在 FastAPI 上开发。
第二阶段(第 2-4 月):将自研的核心引擎层(工作流引擎、RAG 引擎、模型网关)的 API 全部在 FastAPI 上暴露,Flask 侧保留 Dify 原有的用户管理、基础应用管理接口。
第三阶段(第 5-6 月):逐步将 Dify 原有的高频接口(对话、工作流执行等)迁移到 FastAPI,使用 Feature Flag 控制路由切换。
第四阶段(第 7 月+):全面切换到 FastAPI,移除 Flask 依赖。
# FastAPI 应用入口示例
from fastapi import FastAPI, Depends
from fastapi.middleware.cors import CORSMiddleware
app = FastAPI(
title="AI Workflow Platform API",
version="2.0.0",
docs_url="/api/v2/docs",
openapi_url="/api/v2/openapi.json",
)
# 中间件链
app.add_middleware(CORSMiddleware, allow_origins=["*"])
app.add_middleware(TenantMiddleware) # 租户识别
app.add_middleware(AuthMiddleware) # JWT 认证
app.add_middleware(RateLimitMiddleware) # 限流
app.add_middleware(TelemetryMiddleware) # OpenTelemetry 追踪
# SSE 端点:工作流执行实时推送
from fastapi.responses import StreamingResponse
@app.get("/api/v2/executions/{execution_id}/stream")
async def stream_execution(execution_id: str):
async def event_generator():
async for event in execution_bus.subscribe(execution_id):
yield f"data: {event.model_dump_json()}\n\n"
return StreamingResponse(
event_generator(),
media_type="text/event-stream"
)
八、技术选型总览
| 层次 | 组件 | 选型 | 版本 | 说明 |
| ---- | -------- | --------------------------- | --------------- | ---------------------- |
| 前端 | UI 框架 | Next.js + React | 14.x + 18.x | 继承 Dify 前端架构 |
| 前端 | 工作流编辑器 | React Flow | 12.x | 节点式可视化编辑 |
| 前端 | 状态管理 | Zustand | 5.x | 轻量、适合画布状态管理 |
| 后端 | Web 框架 | FastAPI(渐进替代 Flask) | 0.115+ | 异步高性能,类型安全 |
| 后端 | 异步队列 | Celery + Redis | 5.4 + 7.x | 继承 Dify,增加 Beat 定时任务 |
| 后端 | 工作流引擎 | 自研 DAG + transitions | transitions 9.x | 状态机驱动的 DAG 执行 |
| 后端 | Agent 框架 | 自研多 Agent 协作 | — | Protocol ABC + 三种预置模式 |
| 后端 | RAG 引擎 | 自研 + unstructured + marker | — | 语义分块 + 混合检索 + Reranker |
| 后端 | 插件系统 | pluggy + importlib.metadata | 1.5.x | Hook 式插件架构 |
| 后端 | LLM 网关 | 自研 ABC + LiteLLM | LiteLLM 1.55+ | 统一多模型接入 |
| 后端 | 熔断器 | pybreaker | 2.x | 模型调用熔断保护 |
| 数据 | 主数据库 | PostgreSQL | 16.x | 支持 RLS 多租户隔离 |
| 数据 | 缓存/消息 | Redis | 7.x | 缓存 + Pub/Sub + Streams |
| 数据 | 向量数据库 | Milvus / Qdrant | 2.4 / 1.12 | 可插拔设计 |
| 数据 | 对象存储 | MinIO / S3 | — | 文档与模型产物存储 |
| 数据 | DB 迁移 | Alembic | 1.14+ | 版本化 Schema 管理 |
| 数据 | 评估框架 | RAGAS | 0.2+ | RAG 质量自动化评估 |
| 基础设施 | 容器编排 | Docker Compose + K8s | — | 开发精简 / 生产完整 |
| 基础设施 | 可观测性 | OpenTelemetry + Grafana | — | 链路追踪 + 指标监控 |
| 基础设施 | CI/CD | GitHub Actions / GitLab CI | — | 自动化测试与部署 |
九、技术路线图(详细)
9.1 总体路线图
整个二次开发分为四个阶段,建议总周期 9 个月。
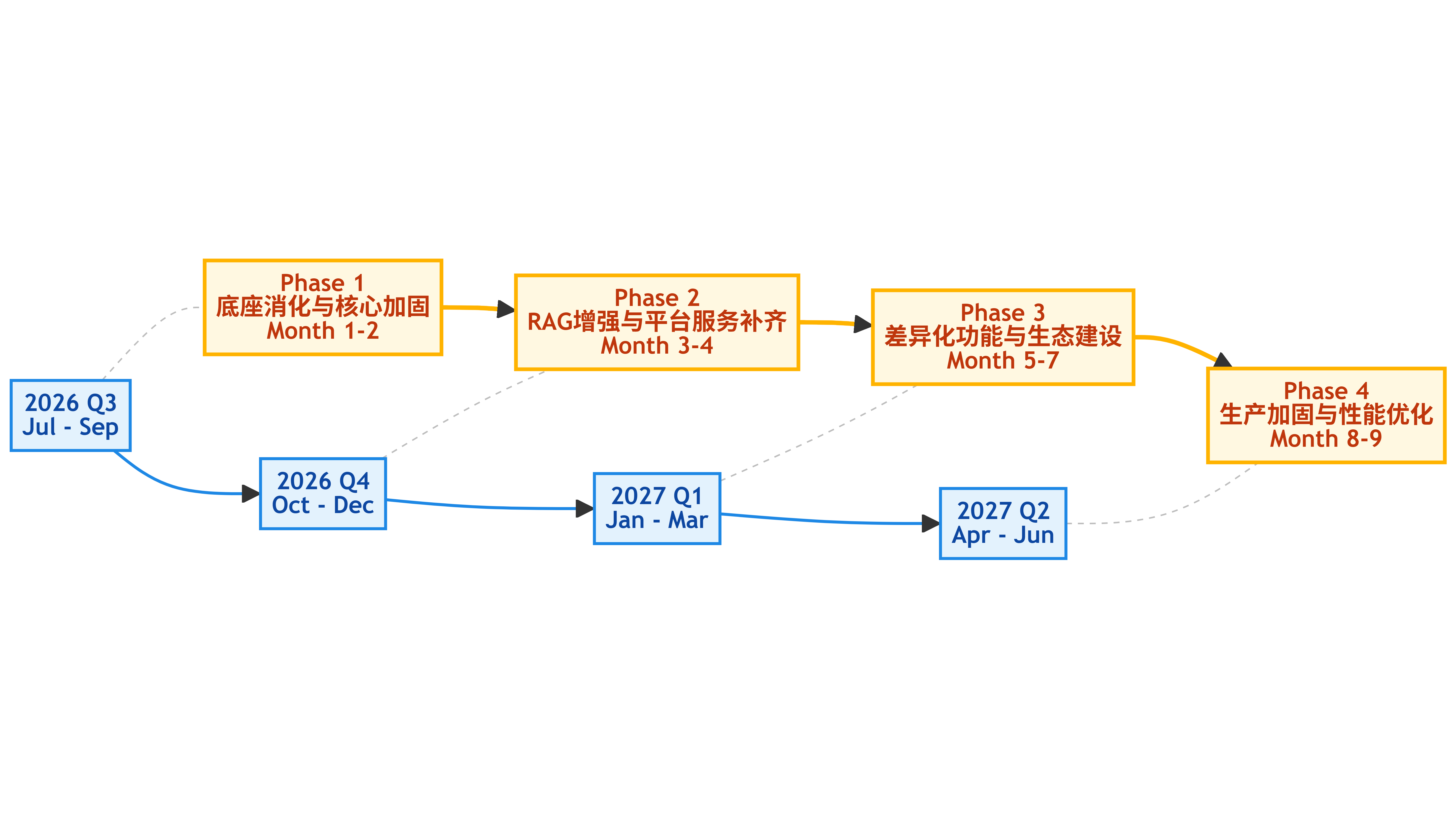
9.2 第一阶段:底座消化与核心加固(第 1-2 月)
| 周次 | 任务 | 交付物 | 负责角色 |
| — | --------------------------------------- | -------------------------------- | ----------- |
| W1 | Fork Dify,搭建开发环境,跑通全部测试 | CI 流水线 + 测试报告 | DevOps + 后端 |
| W1 | 梳理 Dify 后端代码结构,建立架构知识库 | 架构文档 + 代码注释 | 后端 |
| W2 | 精简 Docker 部署:合并容器至 5-6 个 | docker-compose.yml | DevOps |
| W2 | 搭建 FastAPI 应用实例,与 Flask 并行运行 | FastAPI 骨架 + ASGI 中间件 | 后端 |
| W3 | 改造工作流引擎:引入 transitions 状态机 | state_machine.py + 单元测试 | 后端 |
| W3 | 实现子工作流节点(Sub-Workflow) | nodes/sub_workflow.py | 后端 |
| W4 | 实现断点续跑机制 | checkpoint.py + PostgreSQL 表 | 后端 |
| W4 | 实现 For-Each / While 循环节点 | nodes/for_each.py + while.py | 后端 |
| W5 | 改造模型网关:Fallback Chain + Circuit Breaker | fallback.py + circuit_breaker.py | 后端 |
| W5 | 集成 LiteLLM 作为长尾模型适配层 | litellm_provider.py | 后端 |
| W6 | 引入 asyncio 轻量执行器用于 LLM 调用节点 | async_executor.py | 后端 |
| W6 | 前端:调试模式 MVP(断点 + 单步执行) | React Flow 增强 | 前端 |
| W7 | 集成测试 + 性能基线测试 | 测试报告 + 性能基线 | 全员 |
| W8 | 文档整理 + Phase 1 Release | v0.1-alpha 发布 | 全员 |
Phase 1 里程碑交付物:可运行的 v0.1-alpha 版本,包含精简部署(5-6 容器)、状态机驱动的工作流引擎(支持子工作流、循环、断点续跑)、带 Fallback 和熔断的模型网关、调试模式 MVP。
9.3 第二阶段:RAG 增强与平台服务补齐(第 3-4 月)
| 周次 | 任务 | 交付物 | 负责角色 |
| — | -------------------------------- | -------------------------- | ------- |
| W9 | 文档解析器升级:unstructured + marker 集成 | parser/pdf_parser.py 等 | AI + 后端 |
| W9 | 语义分块器实现 | chunker/semantic.py | AI |
| W10 | 混合检索器:向量 + BM25 双通道 | retriever/hybrid.py | 后端 |
| W10 | BGE-Reranker 重排序集成 | retriever/reranker.py | AI |
| W11 | Self-RAG 模式实现 | advanced/self_rag.py | AI |
| W11 | Corrective RAG 模式实现 | advanced/corrective_rag.py | AI |
| W12 | RAGAS 评估框架集成 + 质量基线 | evaluator.py + 评估报告 | AI |
| W12 | 知识库管理 UI 重构 | 前端知识库页面 | 前端 |
| W13 | ABAC 权限引擎实现 | auth/abac.py | 后端 |
| W13 | SSO 集成(OIDC + SAML 2.0) | auth/sso.py | 后端 |
| W14 | PostgreSQL RLS 多租户隔离 | tenant/rls.py + 迁移脚本 | 后端 |
| W14 | 计费系统:Redis 实时计量 + 账单生成 | billing/ 模块 | 后端 |
| W15 | 审计日志系统 | audit/ 模块 | 后端 |
| W15 | 运营中心 Dashboard UI | 用量/计费/审计页面 | 前端 |
| W16 | 集成测试 + Phase 2 Release | v0.2-beta 发布 | 全员 |
Phase 2 里程碑交付物:v0.2-beta 版本,包含三代 RAG 管线(语义分块 + 混合检索 + Reranker + Self/Corrective RAG)、RAGAS 评估基线、ABAC 权限、SSO 集成、多租户隔离、计费与审计系统。
9.4 第三阶段:差异化功能与生态建设(第 5-7 月)
| 周次 | 任务 | 交付物 | 负责角色 |
| — | --------------------------------------- | ----------------------------- | ------- |
| W17 | Agent 引擎:AgentProtocol ABC + 单 Agent 增强 | agent/protocol.py | 后端 |
| W17 | 记忆管理层:短/中/长期记忆 | agent/memory.py | AI + 后端 |
| W18 | 多 Agent 协作:Orchestrator-Worker 模式 | agent/orchestrator.py | 后端 |
| W18 | 多 Agent 协作:Debate + Pipeline 模式 | agent/debate.py + pipeline.py | 后端 |
| W19 | 工具选择推理(Tool Selection Reasoning) | agent/tool_reasoning.py | AI |
| W19 | MCP Server 实现 | mcp/server.py | 后端 |
| W20 | 应用模板市场:后端 + 管理功能 | 模板 CRUD API | 后端 |
| W20 | 应用模板市场:前端 UI | 模板市场页面 | 前端 |
| W21 | 预置 20+ 行业模板 | 模板 YAML + 工作流定义 | 产品 + AI |
| W21 | 插件系统升级:pluggy Hook + 沙盒隔离 | plugins/ 模块 | 后端 |
| W22 | 插件开发者 SDK + 文档站 | SDK + 开发者文档 | 后端 + 产品 |
| W22 | 协作编辑:Yjs + WebSocket 集成 | 协作编辑功能 | 前端 + 后端 |
| W23 | 前端编辑器增强:子流程折叠 + 小地图 | React Flow 高级功能 | 前端 |
| W23 | 通知节点:邮件/钉钉/飞书/企微集成 | 集成插件 | 后端 |
| W24 | Phase 3 Release | v0.3-rc 发布 | 全员 |
Phase 3 里程碑交付物:v0.3-rc 版本,包含多 Agent 协作框架、MCP Server、应用模板市场(20+ 模板)、插件市场与开发者 SDK、协作编辑能力、增强版可视化编辑器。
9.5 第四阶段:性能优化与生产加固(第 8-9 月)
| 周次 | 任务 | 交付物 | 负责角色 |
| — | --------------------------------- | -------------------------- | ----------- |
| W25 | Celery Worker 池调优 + asyncio 执行器优化 | 性能调优报告 | DevOps + 后端 |
| W25 | Redis 集群化部署 + 数据库读写分离 | 架构升级方案 | DevOps |
| W26 | API 限流(令牌桶)+ 输入校验加固 | rate_limit.py + validators | 后端 |
| W26 | 安全审计:SQL 注入 / XSS / CSRF 防护 | 安全扫描报告 | 后端 |
| W27 | 压力测试:100 并发工作流 + 1000 并发对话 | 压测报告 + 容量规划 | DevOps |
| W27 | Grafana 监控 Dashboard + 告警规则 | 监控体系 | DevOps |
| W28 | Kubernetes Helm Charts 编写 | helm/ 目录 | DevOps |
| W28 | 生产部署文档 + 运维手册 | 文档集 | DevOps + 后端 |
| W29 | 全量回归测试 + 渗透测试 | 测试报告 | 全员 |
| W30 | 性能基线对比 + Phase 4 Release | v1.0 正式版发布 | 全员 |
Phase 4 里程碑交付物:v1.0 正式版,通过压力测试(100 并发工作流 / 1000 并发对话)、安全审计、完整的监控告警体系、K8s Helm Charts、生产部署文档与运维手册。
十、可落地的具体方向
10.1 第一批落地的 5 个行业场景
二次开发不应追求"通用万能",而应在 5 个高价值行业场景中做深做透,形成标杆案例。
场景一:企业知识库问答
典型客户为中大型企业,痛点是内部文档散落在多个系统(Confluence、飞书文档、本地文件)中,员工检索效率低。落地方案是构建统一知识库,接入多源文档(Confluence API 同步 + 飞书文档 API + 本地文件上传),利用增强版 RAG 引擎实现精准问答。差异化价值在于混合检索 + Reranker 确保召回质量,以及 Graph RAG 处理跨文档的关联性问题(如"A 项目用了 B 技术,B 技术的替代方案是什么")。
场景二:智能客服工作台
典型客户为电商、SaaS 公司,痛点是客服人力成本高、回答质量不一致。落地方案是构建多轮对话 Agent,集成知识库(产品文档 + FAQ + 历史工单),支持自动回答 + 人工介入无缝切换。差异化价值在于多 Agent 协作——Orchestrator Agent 判断意图,Knowledge Agent 检索文档,Order Agent 查询订单系统,三个 Agent 协同给出完整回答。
场景三:数据分析助手
典型客户为数据驱动型企业,痛点是非技术人员无法自助查询数据。落地方案是构建 Text-to-SQL Agent,用户用自然语言提问,Agent 自动生成 SQL、执行查询、将结果可视化为图表。差异化价值在于工作流引擎的循环能力——Agent 可以先执行查询、检查结果合理性、自动修正 SQL 重试,直到结果满意。
场景四:合同审查工作流
典型客户为法务部门、律师事务所,痛点是合同审查耗时且容易遗漏。落地方案是构建文档解析 + RAG + LLM 的流水线工作流:上传合同 → 解析全文 → 对照法规/公司模板逐条比对 → 标注风险条款 → 生成审查报告。差异化价值在于增强版文档解析(准确处理合同中的嵌套表格、附录引用)和长文档处理能力。
场景五:代码审查与文档生成
典型客户为研发团队,痛点是 Code Review 耗时、API 文档维护滞后。落地方案是构建 Git 集成工作流:监听 PR 事件 → 分析代码变更 → 生成 Review 意见 → 更新 API 文档 → 通过 MCP Server 直接集成到 IDE。差异化价值在于 MCP 接入让开发者在 Cursor / VS Code 中直接使用平台能力。
10.2 落地执行要点
每个行业场景的落地应遵循统一的四步法:
第一步,需求深潜(2 周):与 2-3 个目标客户深度访谈,明确核心场景、数据特征、集成需求、成功标准。输出一份场景需求规格文档。
第二步,场景 MVP(4 周):基于平台通用能力,为该场景构建定制化工作流模板和节点。比如客服场景需要额外的"订单查询"节点和"人工转接"节点。
第三步,效果验证(2 周):用客户的真实数据建立 RAGAS 评估基线,运行 A/B 测试对比人工 vs 平台效果。核心指标包括:问答准确率(目标 >85%)、首次响应时间(目标 <3s)、客户满意度(目标 >4.0/5.0)。
第四步,规模化复制(2 周):将场景 MVP 打包为应用模板上架模板市场,编写场景化文档和最佳实践,形成可复制的解决方案包。
10.3 技术攻坚优先级
按照对用户体验和产品竞争力的影响程度排序,技术攻坚的优先级如下:
P0(必须在 Phase 1-2 解决):工作流引擎的状态机改造和断点续跑(这是所有高级功能的基础);混合检索 + Reranker 的 RAG 管线(这是知识库问答质量的决定性因素);模型网关的 Fallback Chain(这直接影响服务可用性)。
P1(Phase 2-3 解决):语义分块和高级 RAG 模式(进一步提升 RAG 质量的上限);多 Agent 协作框架(这是差异化竞争力的核心);MCP Server(这是生态接入的关键通道)。
P2(Phase 3-4 解决):协作编辑(锦上添花功能);Graph RAG(复杂场景增强);插件市场和开发者生态(长期生态建设)。
10.4 关键性能指标(KPI)
| 指标 | Phase 1 目标 | Phase 4 目标 | 说明 |
| ---------------- | ---------- | ---------- | -------------- |
| 工作流执行延迟(10 节点) | < 5s | < 2s | 从触发到全部节点完成 |
| LLM 调用首 Token 延迟 | < 800ms | < 500ms | 流式输出的第一个 Token |
| RAG 检索准确率(RAGAS) | > 0.70 | > 0.85 | 基于评估数据集 |
| 并发工作流执行数 | 20 | 100 | 单 Worker 节点 |
| 并发对话数 | 200 | 1000 | 整个集群 |
| 系统可用性 | 99.5% | 99.9% | 月度统计 |
| 模型调用成功率 | 95% | 99.5% | 含 Fallback 降级 |
| 部署容器数 | 6 | 5(精简模式) | 最小部署规模 |
十一、团队配置建议
建议核心团队 8-12 人,角色配置如下:后端工程师 3-4 人(其中 1 人专注工作流/Agent 引擎,1 人专注 RAG 引擎,1-2 人负责平台服务层);前端工程师 2-3 人(其中 1 人专注工作流编辑器,1-2 人负责应用界面和模板市场);AI/算法工程师 1-2 人(专注 RAG 优化、模型调优、评估体系);DevOps 工程师 1 人(基础设施、CI/CD、监控);产品经理 1 人(需求管理、模板设计、用户调研)。
十二、风险与应对
风险一:Dify 上游版本迭代冲突。 Dify 社区更新频繁,二次开发分支与上游的 merge 成本会随时间增大。应对策略是尽量通过插件和扩展点实现定制,减少对核心代码的直接修改;建立定期(每月)与上游同步的机制;将自研代码集中在独立的 Python package(src/)中,通过组合而非修改的方式集成。
风险二:Flask 到 FastAPI 的迁移风险。 Dify 后端基于 Flask,而 FastAPI 在异步性能和类型安全方面明显优于 Flask。但全面迁移工作量大且风险高。应对策略是采用渐进式迁移——新增模块一律使用 FastAPI,旧模块保持 Flask 运行,通过 ASGI 中间件统一路由,逐步替换。
风险三:工作流引擎复杂度爆炸。 引入子工作流、循环、断点续跑等特性后,引擎的状态管理复杂度会指数级增长。应对策略是先做好状态机的形式化建模和单元测试覆盖,再逐步引入高级特性;每个新特性独立 PR、独立 Feature Flag,出问题可快速回滚。
风险四:RAG 效果的场景依赖性。 RAG 效果高度依赖具体场景的文档类型和查询模式,通用优化不一定在特定场景生效。应对策略是建立 RAGAS 评估基线后,针对 5 个目标行业场景做专项优化和 Benchmark,避免追求"万能 RAG"。
风险五:多 Agent 协作的调试难度。 多 Agent 交互时,问题定位和调试远比单 Agent 困难。应对策略是从第一天就建设完善的 trace 体系(OpenTelemetry),每个 Agent 的每轮思考和行动都记录为 trace span,支持可视化回放。
十三、总结
以 Dify 为底座进行二次开发是当前技术条件下的最优选择——Python 后端生态最丰富、插件体系最完善、社区活跃度最高、架构清晰且可理解。通过六层分层架构设计,每一层职责明确、可独立演进,既能快速出活(第一阶段即可交付可用版本),又保留了长期的架构演进空间。
核心差异化方向聚焦三个点:更强的 RAG 引擎(混合检索 + 高级 RAG 模式)、更灵活的 Agent 协作框架(多 Agent 编排)、以及更开放的生态接入(MCP Server + 插件市场)。
落地策略上,选择 5 个高价值行业场景(企业知识库、智能客服、数据分析助手、合同审查、代码审查)深耕,每个场景遵循"需求深潜 → 场景 MVP → 效果验证 → 规模复制"的四步法,确保技术投入能直接转化为产品竞争力。
评论区