



引言
大模型应用落地正从"单点对话验证"迈向"复杂业务流程规模化"阶段。据行业调研数据显示,超过 95% 的生成式 AI 试点项目最终无法完成规模化落地,核心瓶颈之一就是纯代码开发模式迭代效率低、业务与技术协作成本高、运维复杂度不可控。可视化工作流编排凭借"拖拽搭建、所见即所得、逻辑可追溯、快速迭代"的特性,成为企业突破 AI 落地瓶颈的核心技术路径。
但市面上同类产品技术栈差异极大:用户熟知的 FastGPT 基于 TypeScript 全栈开发,热门的 Flowise 依赖 Node.js 生态,对于核心技术栈为 Python 的 AI 团队而言,技术栈不统一意味着二次开发成本陡增、AI 能力复用困难、运维体系割裂。很多团队在选型时容易陷入"功能看起来全,改起来寸步难行"的困境。
本文将从五个维度系统解答这一问题:上层产品平台全景扫描(哪些成品平台可以二次开发)、底层框架深度评估(Agent/工作流/RAG/基础设施各层最优选型)、二次开发路线决策(从快速魔改到完全自研的三条路径)、LangFlow 定制化实战(完整的二次开发落地方案)、最终选型建议(分层技术栈与场景化推荐),为 Python 技术团队打造专属 AI 能力平台提供从选型到落地的完整路径。
一、Python 生态 AI 工作流编排产品全景扫描
Python 是大模型开发的事实标准语言,从模型推理、RAG 检索到 Agent 协作,核心能力几乎都基于 Python 生态构建。选择同技术栈的编排平台,意味着可以直接复用现有 AI 能力、降低团队学习成本、保障后续深度定制的灵活性。目前市场上的 Python 系产品可分为三大类,分别对应不同的落地阶段和团队需求。
1.1 一站式可视化平台:开箱即用,对标 Dify
这类产品具备完整的前端界面、知识库管理、对话应用、权限体系,部署后即可直接使用,适合非技术团队快速搭建 AI 应用,也可作为底座进行二次开发。
(1)Dify — 行业标杆级全栈平台
Dify 是目前国内最主流的一站式 AI 应用开发平台,后端基于 Python FastAPI 构建,前端采用 React 技术栈,能力覆盖知识库 RAG、可视化工作流、Agent 工具调用、对话应用发布、API 网关等全链路。
- 核心优势:功能均衡完善,工作流引擎支持循环、分支、代码沙盒、变量传递等复杂逻辑;原生支持多租户、RBAC 权限、日志审计等企业级能力;文档与社区生态成熟(GitHub 90k+ Stars)。
- 适用场景:面向企业交付一站式 AI 平台、需要完整知识库与对话应用能力的团队。
- 二次开发局限:架构较重,依赖 PostgreSQL、Redis、向量数据库等多组件;画布基于 ReactFlow 封装但定制自由度有限,修改底层执行逻辑门槛较高。
(2)RAGFlow — 文档深度解析专精平台
RAGFlow(GitHub 83.2k Stars,Apache-2.0)后端基于 Python FastAPI,前端采用 Vue 技术栈,是国内文档解析能力最强的开源 RAG 平台。核心差异化是深度文档理解——基于 5 年数据训练的高精度 OCR,处理印刷体、手写体、表格、公章。模板化的文档解析(不同文档类型用不同模板:Q&A 对、手册、书籍、论文、法规等),保持语义连贯性。检索提供溯源引用(Grounded Citations),可追溯来源减少幻觉。
- 核心优势:对 PDF、扫描件、表格、合同、财报等复杂文档的解析精度远超同类产品;轻量化部署,中文适配优秀。
- 适用场景:法律、金融、政务等以文档知识库为核心的场景。
- 不足:工作流编排能力相对基础,多 Agent 协作、工具调用能力弱于 Dify。更适合作为独立的 RAG 服务通过 API 集成,而非作为库嵌入。
(3)MaxKB — 最轻量的知识库 + Agent 平台
MaxKB(GitHub 21.4k Stars,GPL-3.0)基于 Django + Vue,从简单知识库进化为带工作流引擎和工具库的 AI Agent 平台。无代码嵌入外部企业应用,广泛的 LLM 兼容,多模态处理。1Panel 生态集成,部署运维极轻。
- 核心优势:部署仅需单容器,对硬件要求极低;界面简洁,非技术人员上手成本极低。
- 注意:GPL-3.0 协议要求衍生作品也必须 GPL,这对商业化有限制。无可视化工作流画布,仅支持线性问答流程。
(4)Bisheng — 企业治理最强的 Python 平台
Bisheng(GitHub 11.5k Stars,v2.4.0,Apache-2.0)是 Python + React 技术栈的企业级 AI 应用平台。拥有可视化工作流引擎(支持循环任务、并发、Human-in-the-Loop)、Lingsight Agent 框架、基于 5 年数据训练的高精度 OCR。企业特性最为完善——SSO、严格权限管理、多 Agent 协作、领域专家知识嵌入。已被世界 500 强企业生产使用。
- 作为 Dify 替代底座:Apache-2.0 协议友好,Python + React 架构清晰,企业特性开箱即用。但社区规模(11.5k vs Dify 90k+)和插件生态不如 Dify。如果目标客户主要是大型企业,Bisheng 值得认真评估。
(5)DB-GPT — 私有化离线全栈平台
DB-GPT 以 Python 为核心开发语言,主打完全本地化、私有化的大模型应用平台。原生支持本地大模型(Ollama、Llama.cpp 等)、本地向量库、数据库智能查询 Agent;完全离线部署,满足政企数据合规要求。
(6)Open WebUI — 最受欢迎的自托管 AI 界面
Open WebUI(GitHub 142k Stars,Python FastAPI 后端 + SvelteKit 前端)是 Star 数最高的自托管 AI 项目。提供 ChatGPT 风格的界面、完整的 RBAC/SCIM/SSO 企业认证、本地 RAG、语音/视频通话、图像生成、Python Function Calling、OpenTelemetry 可观测性。
- 定位:更适合作为前端 UI 组件引入而非整体平台底座——它本质上是一个"界面层",不是完整的 AI 应用编排平台。
1.2 开发者向编排工具:面向技术团队的可视化 IDE
这类产品定位为开发者工具,核心价值是将 Python 代码能力可视化,不追求开箱即用的完整业务功能,而是提供极致的自定义扩展能力,适合技术团队搭建专属编排平台。
LangFlow — LangChain 生态原生可视化引擎
LangFlow 由 DataStax 官方开源,后端纯 Python(FastAPI),前端基于 React + ReactFlow,底层完全基于 LangChain 与 LangGraph 生态,是 Python 栈二次开发的首选底座。
- 核心优势:节点扩展成本极低,后端定义输入输出后前端自动渲染配置面板,零前端代码即可新增业务节点;原生支持嵌入 Python 代码片段,可直接调用任意 Python 库;MIT 开源协议,商用无限制;架构轻量,核心依赖少。
- 定位差异:Dify 面向产品/运营人员,主打"不用写代码做应用";LangFlow 面向开发者,主打"可视化编排 Python AI 能力"。
- 不足:原生缺少完整的知识库管理、多租户权限、对话应用市场等企业级功能,需自行扩展。
注:市场上知名度较高的 Flowise 采用 Node.js 后端开发,不属于 Python 技术栈,Python 团队二次开发适配成本极高,不建议纳入选型范围。
1.3 平台选型速查矩阵
| 平台 | Stars | 协议 | 技术栈 | 工作流画布 | 知识库 | 企业权限 | 二开友好度 | 适合场景 |
|---|---|---|---|---|---|---|---|---|
| Dify | 90k+ | Apache-2.0 | Python+React | ✅ 完整 | ✅ 完整 | ✅ RBAC | 中 | 企业级一站式平台 |
| LangFlow | 60k+ | MIT | Python+React | ✅ 完整 | ❌ 需自建 | ❌ 需自建 | 高 | 开发者定制化平台 |
| RAGFlow | 83.2k | Apache-2.0 | Python+Vue | ⚠️ 基础 | ✅ 深度OCR | ⚠️ 有限 | 中 | 文档RAG专精场景 |
| Bisheng | 11.5k | Apache-2.0 | Python+React | ✅ 完整 | ✅ OCR | ✅ SSO | 中高 | 大型企业治理 |
| MaxKB | 21.4k | GPL-3.0 | Django+Vue | ❌ 无 | ✅ 基础 | ⚠️ 有限 | 低 | 轻量知识库问答 |
| Open WebUI | 142k | MIT | Python+Svelte | ❌ 无 | ⚠️ 基础 | ✅ RBAC/SSO | 低 | 自托管AI界面 |
| DB-GPT | 15k+ | Apache-2.0 | Python+React | ✅ 完整 | ✅ 基础 | ⚠️ 有限 | 中 | 私有化离线部署 |
二、底层框架深度评估:四大类核心能力选型
构建一个可视化 AI 工作流编排平台,Python 生态中可二次开发的开源框架按职能可分为四大类。无论选择哪种上层平台,底层框架的选型决定了平台的扩展天花板。下面按"Agent 与多智能体框架"、“工作流与任务编排引擎”、“RAG 与文档智能框架”、"平台级基础设施库"四个维度进行深度评估。
2.1 Agent 与多智能体框架
这类框架负责 Agent 的构建、编排和协作,是工作流平台中"智能体节点"的核心运行时。
LangGraph — 最适合可视化工作流的 Agent 引擎
LangGraph(GitHub 35.2k Stars,v1.2.6,MIT 协议)是 LangChain 团队推出的图状态机 Agent 框架,v1.0 版本已脱离 LangChain 依赖成为独立库。其核心思想是将 Agent 执行建模为有向有状态图——每个节点是一个函数,边定义转移逻辑,全局状态对象在图中流转。原生支持条件分支、循环、子图嵌套,以及崩溃恢复的自动 Checkpointing。
二次开发适配度:5/5(最高)。 LangGraph 的图模型与可视化工作流编辑器是 1:1 映射关系——节点就是画布上的 Block,边就是连线,状态机天然可序列化为 JSON 用于前后端交互。Checkpointing 机制直接支持断点续跑和调试模式(单步执行、状态检视)。LangSmith 提供了开箱即用的可观测性。这是作为工作流引擎底层运行时的最强候选。
CrewAI — 社区最大的多 Agent 协作框架
CrewAI(GitHub 59.1k Stars,v1.14.7,MIT 协议)采用角色驱动的多 Agent 编排模型——每个 Agent 被赋予角色、背景故事和目标,组织成"Crew"协作完成任务。支持自主模式(Agent 自行分工)和精确模式(Flows,显式编排)。已原生支持 MCP 和 A2A(Agent-to-Agent)协议,社区认证开发者超 10 万人。
二次开发适配度:4/5。 角色/任务隐喻在可视化编辑器中非常直观——可以将 Agent 可视化为"团队成员",任务可视化为"工作分配"。Flows 功能提供了确定性编排能力。但其自主协调模式在大规模场景下 Token 消耗较高且结果不够可预测,内部状态管理不如 LangGraph 显式,精确调试的难度更大。适合构建"团队协作"风格的工作流编辑器。
PydanticAI — 类型安全最佳的 Agent 框架
PydanticAI(GitHub 17.9k Stars,v1.107.0,MIT 协议)由 Pydantic 团队开发,核心特色是类型安全——Agent 通过 Pydantic 模型定义,工具通过依赖注入绑定,LLM 输出通过 Schema 校验。风格类似 FastAPI 的开发体验,内置 Pydantic Logfire 遥测。声明式的依赖图可以通过类型注解自动推导,理论上可以自动生成可视化工作流表示。
二次开发适配度:4/5。 代码质量和类型安全性极高,FastAPI 风格的 API 对 Python 开发者非常友好。声明式定义可以被程序化地内省和可视化,这对自动生成画布布局很有价值。社区增长迅速但规模仍小于 LangGraph/CrewAI。多 Agent 协作模式的生产案例相对较少。
smolagents — HuggingFace 生态的代码型 Agent
smolagents(GitHub 27.9k Stars,v1.26.0,Apache-2.0)是 HuggingFace 推出的代码优先 Agent 框架——Agent 的动作是生成并执行 Python 代码,而非 JSON 工具调用。核心逻辑约 1000 行,支持 Docker/E2B 沙盒执行,深度集成 HuggingFace Hub(工具和 Agent 可在 Hub 上分享)。
二次开发适配度:3/5。 社区规模可观,HuggingFace 生态加持有价值。但代码型 Agent 的范式在拖拽式可视化编辑器中不太自然(Agent 写代码而非走预定义路径),更适合面向 ML/AI 从业者的代码优先平台。Hub 分享机制可以作为插件市场的参考设计。
Letta(原 MemGPT)— 长记忆 Agent 运行时
Letta(GitHub 23.4k Stars,v0.16.8,Apache-2.0)的核心创新是分层记忆架构——Agent 拥有固定大小的"核心记忆"(始终在上下文中)、“归档记忆”(向量数据库,Agent 自主管理页入页出)和"召回记忆"(对话历史)。灵感来自操作系统的虚拟内存管理,实现了"无限记忆"的效果。
二次开发适配度:3/5。 是优秀的 Agent 运行时但非工作流编排器——擅长单 Agent 的记忆管理而非多 Agent 协调或 DAG 执行。适合作为平台中"Agent 节点"的内部运行时,而非整体编排引擎。
需要注意的框架: AutoGen(Microsoft,59k Stars)已进入维护模式,不再有功能更新,Microsoft 正转向统一的 Agent Framework;OpenAI Swarm 已被废弃,替换为 OpenAI Agents SDK;PocketFlow(10.8k Stars)核心仅 100 行,过于精简,需要自建几乎所有基础设施;AG2(AutoGen 社区分叉,4.7k Stars)社区太小,架构较旧;Semantic Kernel(28.2k Stars)微软推出的多语言 SDK,Python 支持完善但可视化适配度一般,更适合 .NET 技术栈团队。
Agent 框架选型矩阵:
| 框架 | Stars | 协议 | 可视化适配 | 代码质量 | 扩展性 | 社区 | 综合评分 |
|---|---|---|---|---|---|---|---|
| LangGraph | 35.2k | MIT | 5 | 5 | 5 | 5 | 5/5 |
| CrewAI | 59.1k | MIT | 4 | 4 | 4 | 5 | 4/5 |
| PydanticAI | 17.9k | MIT | 4 | 5 | 4 | 4 | 4/5 |
| smolagents | 27.9k | Apache-2.0 | 3 | 4 | 3 | 4 | 3/5 |
| Letta | 23.4k | Apache-2.0 | 3 | 4 | 3 | 4 | 3/5 |
推荐组合:以 LangGraph 作为工作流引擎的底层运行时(图执行 + 状态管理 + Checkpoint),Agent 节点内部可选集成 CrewAI(多 Agent 协作场景)或 PydanticAI(类型安全场景)。Letta 可作为长期记忆 Agent 的专用运行时。
2.2 工作流与任务编排引擎
这类框架负责任务的异步执行、调度和状态管理,是工作流引擎的"调度底座"。
Prefect — 最适合 AI 工作流的 Python 编排引擎
Prefect(GitHub 22.6k Stars,v3.7.5,Apache-2.0)是新一代 Python 工作流编排引擎。v3.x 采用装饰器式 API——@flow 和 @task 装饰普通 Python 函数即可纳入编排。DAG 是动态推导的(从数据依赖自动发现),无需静态定义。内建状态跟踪(Pending/Running/Completed/Failed/Crashed)、声明式重试策略(指数退避 + 抖动 + 条件重试)、结果缓存(避免重复 LLM 调用)、并发限制(防止 LLM API 被限流)、事件驱动自动化(触发重索引或微调任务),以及完整的 Web UI 和监控。
二次开发适配度:Excellent。 Pythonic 的 API 使得将 LLM 调用、Embedding 生成、RAG 步骤包装为 Task 几乎零成本。动态 DAG 构造支持条件分支(根据输入路由到不同模型)。缓存机制天然适合 LLM 调用去重。Web UI 可以作为管理工作流执行的后端 Dashboard。
Temporal — 长时运行工作流的最佳选择
Temporal(GitHub 21.1k Stars,Python SDK v1.29.0,MIT 协议)的核心特性是持久化执行——工作流状态由 Temporal Server(Go 编写)自动持久化,Worker 崩溃后新 Worker 可从断点处恢复,工作流本身永不因基础设施问题"失败"。工作流定义为原生 Python 代码(支持任意循环、条件、并行、子工作流),表达能力无上限。支持 Human-in-the-Loop(通过 Signal 和 Query 在运行中介入)、OpenTelemetry 集成。
二次开发适配度:Excellent。 持久化执行是长时 AI 工作流(多小时文档处理、微调流水线)的杀手级特性。Activity 重试配合"不可重试错误类型"可以优雅处理 LLM API 故障(429/503 重试,400 直接失败)。代价是需要部署 Temporal Server(Go 二进制 + 数据库),运维复杂度高于 Prefect。
Celery — 经典分布式任务队列
Celery(GitHub 28.6k Stars,v5.6.2,BSD-3)是 Python 生态最成熟的任务队列。Canvas 原语(chain/group/chord/starmap)可以组合基础 AI 流水线。结果后端追踪任务状态。Flower 提供 Web 监控。但缺少 DAG 可视化、工作流级状态管理、持久化执行等高级特性,复杂多步 AI 工作流需要大量手动基础设施。
二次开发适配度:Moderate。 在高吞吐任务处理(百万级任务/分钟)方面久经验证。Dify 本身就是基于 Celery 构建的。但作为 AI 工作流平台的唯一调度引擎不够用——建议保留 Celery 作为底层任务分发层,上层引入 LangGraph 或 Prefect 做 DAG 编排。
其他选项: Dagster(15.7k Stars)面向数据资产编排,适合 ML 训练/评估/部署流水线,但不适合实时请求/响应型 AI 工作流。Dramatiq(5.3k Stars)比 Celery API 更现代但缺少 DAG 能力。Huey(6k Stars)和 Arq(3k Stars,已进入维护模式)过于轻量。
工作流引擎选型矩阵:
| 框架 | Stars | 协议 | DAG 支持 | 状态管理 | 持久执行 | 监控 | AI 适配 |
|---|---|---|---|---|---|---|---|
| LangGraph | 35.2k | MIT | 原生图 | 状态机 | Checkpoint | LangSmith | Excellent |
| Prefect | 22.6k | Apache-2.0 | 动态推导 | 一等公民 | 否 | Web UI | Excellent |
| Temporal | 21.1k | MIT | 代码即图 | 持久化 | 是 | Web UI + CLI | Excellent |
| Celery | 28.6k | BSD-3 | Canvas 有限 | 结果后端 | 否 | Flower | Moderate |
| Dagster | 15.7k | Apache-2.0 | 原生 DAG | 资产物化 | 否 | Dagster UI | Good(数据向) |
推荐组合:LangGraph 作为 DAG 图执行引擎(与可视化编辑器直接映射)+ Celery 作为异步任务分发层(继承 Dify 现有架构)+ Temporal 作为企业版高级选项(长时运行 + 持久化执行场景)。
2.3 RAG 与文档智能框架
这类框架负责文档解析、分块、检索和答案生成,是平台"知识库检索节点"的核心能力来源。
LlamaIndex — 最全面的 RAG 库
LlamaIndex(GitHub 50.2k Stars,MIT 协议)是 Python 生态中功能最丰富的 RAG 框架。通过 LlamaHub 提供 160+ 数据连接器(PDF、DOCX、HTML、数据库、API、Notion、Slack、GitHub 等)。分块策略包括 SentenceSplitter、TokenTextSplitter、SentenceWindowNodeParser、HierarchicalNodeParser 等多种。检索能力最为全面——向量检索、关键词检索、知识图谱检索、混合检索、Reranker 重排序、Query 路由、Agentic 检索,以及子问题递归、树状摘要等高级模式。向量数据库集成 40+ 种(Chroma、Pinecone、Weaviate、Qdrant、Milvus、FAISS、pgvector 等)。插件化架构,llama-index-core 为基础,每个集成独立为包。
二次开发适配度:Exceptional。 作为平台 RAG 引擎的核心库最为合适——接口定义完善(BaseRetriever、BaseNodeParser 等 ABC),自定义组件开发清晰,企业级支持到位。
Haystack — 管线化 RAG 的最佳选择
Haystack(GitHub 25.6k Stars,v2.x,Apache-2.0)由 deepset 团队开发,核心设计是组件化管线(Pipeline)——每个组件通过 @component 装饰器定义,输入输出有类型校验,Pipeline 自动验证连线合法性。v2.x 支持循环和条件分支。检索方面支持稠密检索、稀疏检索(BM25/TF-IDF)、混合检索(RRF 融合)、Contextual Retrieval + Reranking。向量数据库集成 15+ 种。组件可通过 Haystack Hub 分享。Apache-2.0 协议对企业更友好。
二次开发适配度:Excellent。 组件化管线与可视化编辑器的"节点 + 连线"模型高度吻合。类型校验的输入输出使得连线合法性可以在前端画布上实时校验。Pipeline 的可测试性在同类框架中最强。
RAGFlow — 文档理解最深的 RAG 引擎
RAGFlow(GitHub 83.2k Stars,Apache-2.0)的核心差异化是深度文档理解——基于 5 年数据训练的高精度 OCR,处理印刷体、手写体、表格、公章。模板化的文档解析(不同文档类型用不同模板:Q&A 对、手册、书籍、论文、法规等),保持语义连贯性。检索提供溯源引用(Grounded Citations),可追溯来源减少幻觉。
二次开发适配度:Moderate。 更适合作为独立的 RAG 服务通过 API 集成,而非作为库嵌入。如果平台的核心价值主张是"深度文档理解",可以将 RAGFlow 部署为后端微服务。
Kotaemon — 多模态 RAG 与引用可视化
Kotaemon(GitHub 25.5k Stars,Apache-2.0)特色是浏览器内 PDF 阅读器 + 引用高亮 + 相关性评分。支持表格、图表等多模态文档理解。检索管线包含全文搜索 + 向量检索 + Reranker + 问题分解。支持 GraphRAG(知识图谱检索)。基于 Gradio 构建 UI。
二次开发适配度:Good。 引用可视化和多模态理解是有价值的差异化功能,可以作为平台"检索测试"页面的参考实现。
RAG 框架选型矩阵:
| 框架 | Stars | 协议 | 文档解析 | 分块策略 | 检索方法 | 向量库集成 | 扩展性 |
|---|---|---|---|---|---|---|---|
| LlamaIndex | 50.2k | MIT | 160+连接器 | 多种策略 | 最全面 | 40+ | Exceptional |
| Haystack | 25.6k | Apache-2.0 | PDF/DOCX/HTML | 可配置 | Pipeline式 | 15+ | Excellent |
| RAGFlow | 83.2k | Apache-2.0 | 深度OCR | 模板化 | 溯源引用 | 内置 | Moderate |
| Kotaemon | 25.5k | Apache-2.0 | 多模态 | 可配置 | 混合+GraphRAG | 多种 | Good |
推荐组合:LlamaIndex 作为核心 RAG 库(检索引擎 + 数据连接器 + 向量库抽象)+ Haystack 的 Pipeline 设计理念(组件化、类型校验、可测试)+ RAGFlow 作为高级文档理解的可选后端服务。
2.4 平台级基础设施库
这类库不是独立框架,而是构建平台时不可或缺的基础组件,决定了平台的工程化水平和可维护性。
后端 Web 框架
FastAPI(99.4k Stars,v0.137.2,MIT)是 AI 平台后端的实际标准——原生异步、Pydantic 类型安全、自动 OpenAPI 文档、依赖注入。每个 AI 工具库都优先提供 FastAPI 示例。是首选方案。
Litestar(8.3k Stars,v2.24.0,MIT)架构上优于 FastAPI——内建插件系统、DTO 支持、Channel 系统(WebSocket/SSE)、更规范的依赖注入。性能基准测试中某些场景比 FastAPI 快 2-3 倍。社区较小但架构更成熟,值得关注的替代选项。
插件系统
pluggy(1.6.0,MIT)+ importlib.metadata entry points 是 Python 插件系统的最佳组合。pluggy 提供 Hook 规范和插件注册/调用机制(被 pytest 使用),entry points 提供标准 Python 包级别的插件发现。两者结合实现了"定义 Hook → 第三方实现 → pip install 即可用"的开发者体验。
建议为平台定义以下核心 Hook:
class WorkflowPluginSpec:
"""工作流平台插件 Hook 规范"""
def register_node_types(self) -> list:
"""注册自定义节点类型"""
def register_llm_providers(self) -> list:
"""注册 LLM Provider"""
def on_workflow_start(self, workflow, context):
"""工作流开始前触发"""
def on_node_execute(self, node, input_data) -> dict | None:
"""节点执行时触发,可修改输入"""
def on_workflow_complete(self, workflow, result):
"""工作流完成后触发"""
def register_mcp_tools(self) -> list:
"""注册 MCP 工具"""
MCP(Model Context Protocol)SDK
FastMCP(25.7k Stars,v3.4.2,Apache-2.0)是构建 MCP Server 的首选——装饰器式 API(@mcp.tool())、5-10 行代码即可创建 Server、支持 OpenAPI → MCP 桥接(将 FastAPI 端点暴露为 MCP 工具)、支持 Server 组合与代理。由 Prefect 创始人维护,构建在官方 MCP SDK 之上。
官方 MCP Python SDK(23.4k Stars,v1.28.0,MIT)是规范参考实现,支持 stdio/SSE/Streamable HTTP 传输协议。适合做 MCP Client 端集成(连接外部 MCP Server 导入工具)。
推荐:Server 端用 FastMCP(开发效率高),Client 端用官方 SDK(完全协议控制)。
LLM 抽象与增强库
这些库服务于不同层次,互补而非竞争:
- LiteLLM(50.9k Stars,v1.89.2,MIT)— 模型路由与网关层,统一接口覆盖 100+ Provider、代理模式部署、成本追踪、负载均衡、故障转移。注意:2025 年曾发生供应链攻击事件,使用时必须锁定版本并审计。
- Instructor(13.2k Stars,v1.15.3,MIT)— 结构化输出引擎,用 Pydantic 模型约束 LLM 输出,自动重试直到 Schema 合规。对任何需要可靠 LLM 输出的工作流节点(实体提取、分类、数据转换)都是必备库。
- Outlines(14k Stars,v1.3.0,Apache-2.0)— 本地模型约束层,在 Token 级别做受限解码,保证输出严格符合 JSON Schema / 正则 / 上下文无关文法。仅适用于本地模型(vLLM / llama.cpp),不适用于 API 模型。
- DSPy(35.2k Stars,v3.2.1,MIT)— 智能提示优化层,定义模块和行为,DSPy 编译器根据评估数据自动优化 Prompt。适合 RAG 节点、多步推理链、分类节点等 Prompt 工程瓶颈场景。
推荐的四层集成架构:
[用户请求]
│
▼
[工作流引擎] ──── [DSPy] (优化后的 Prompt/Module)
│
▼
[节点执行器] ──── [Instructor] (Pydantic 结构化输出保证)
│
▼
[LiteLLM 代理] ──── [OpenAI / Anthropic / 通义千问 / DeepSeek / ...]
│
▼ (仅本地模型)
[Outlines] ──── [vLLM / llama.cpp] (Token 级约束)
三、二次开发路线选型:从快速魔改到完全自研
打造企业专属的可视化工作流平台,并非只有"从零开发"一条路。根据团队规模、业务需求、交付周期的不同,共有三条典型技术路线。
3.1 路线一:成品平台直接二次开发
基于成熟的开源平台进行功能扩展、界面定制、系统集成,是大多数团队的首选方案。
- 核心优势:开发周期最短,1-2 周即可产出可用版本;复用成熟的画布引擎、执行调度、错误处理等基础能力。
- 核心劣势:受限于原有架构,深度定制有一定约束;若侵入式修改核心源码,后续同步官方版本成本较高。
- 选型细分:若需要完整知识库、权限、对话应用,优先选择 Dify;若核心需求是工作流编排、Python 深度集成、快速扩展节点,优先选择 LangFlow。
3.2 路线二:前后端组件拼装开发
前端选用成熟的拖拽画布库,后端选用 Python 工作流执行引擎,自主拼装搭建完整平台。
-
前端画布库选型:
- ReactFlow:AI 工作流领域的事实标准,Dify、LangFlow 均基于其开发;社区生态最完善,自定义节点、连线、端口高度灵活。
- LogicFlow:腾讯开源的业务流程编辑器,Vue 生态友好,中文文档完善,适合国内政企后台系统。
- AntV X6:阿里开源的工业级拓扑图引擎,超大节点渲染性能稳定,适合超大规模工作流场景。
-
后端执行引擎选型:
- LangGraph:AI 场景首选,原生支持大模型、Agent、RAG,状态管理能力强。
- SpiffWorkflow:纯 Python 通用 BPMN 引擎,支持标准流程调度、分支、条件、子流程,适合 AI + 业务审批的混合场景。
-
核心优势:前后端完全自主可控,定制自由度极高。
-
核心劣势:开发周期长,通常需要 1-2 个月;需要自行解决工作流存储、日志、监控、异常处理等配套能力。
3.3 路线三:完全从零自研
所有前后端代码全部自主编写,不依赖任何第三方编排产品。
- 核心优势:100% 知识产权,完全不受制于上游开源项目。
- 核心劣势:开发成本最高,周期最长;需要踩完所有底层技术坑。
- 适用场景:长期独立产品化、对可控性要求极高的头部企业。
3.4 选型决策矩阵
| 技术路线 | 开发周期 | 自定义自由度 | 内置业务能力 | 维护成本 | 适合团队 |
|---|---|---|---|---|---|
| 魔改 LangFlow | 1-2 周 | 中高(节点易扩展,架构固定) | 弱(无原生知识库/权限) | 低 | Python 技术团队、快速交付内部工具 |
| 魔改 Dify | 2-3 周 | 中等(画布改动受限) | 强(全链路内置) | 中 | 企业级平台、需要完整 RAG/对话能力 |
| 画布库 + Python 引擎拼装 | 1-2 个月 | 高 | 无,全部自行开发 | 中高 | 有前后端团队、需要深度定制 |
| 完全从零自研 | 3 个月以上 | 极高 | 无 | 高 | 独立产品、极致可控需求 |
对于绝大多数 Python 技术团队而言,基于 LangFlow 进行二次开发是综合性价比最高的选择:它既提供了成熟的可视化画布与执行引擎,又保留了 Python 生态的完全开放性,能以最低成本实现定制化需求。
四、实战指南:基于 LangFlow 的定制化编排平台开发
LangFlow 的核心设计优势在于"前后端约定大于配置"——开发者只需在 Python 后端定义组件的输入、输出与执行逻辑,前端会自动生成对应的拖拽节点与配置面板,完全不需要编写前端代码。这种机制让 Python 团队可以专注于业务能力本身,极大降低了可视化平台的开发门槛。
以下改造基于 LangFlow v1.x 稳定版,全程遵循"最小侵入核心源码"原则,所有定制逻辑与官方源码解耦,便于后续同步官方版本更新。
4.1 开发环境搭建与目录规划
环境准备
# 1. Fork官方仓库后克隆到本地
git clone https://github.com/langflow-ai/langflow.git
cd langflow
# 2. 创建Python虚拟环境并安装依赖
python -m venv venv
source venv/bin/activate # Windows执行 venv\Scripts\activate
pip install -e .[dev]
启动模式选择
-
纯后端开发模式:只开发自定义节点、对接后端系统,可直接复用内置打包的前端:
langflow run --dev --port 7860 -
前后端分离模式:需要修改前端界面、定制品牌样式,分别启动前后端实现热更新:
# 终端1:启动后端API服务 langflow run --dev --backend-only --port 7860 # 终端2:启动前端开发服务 cd src/frontend npm install npm run dev
目录结构规划
为了后续升级维护,必须将自定义代码与官方源码物理隔离:
langflow-project/
├── src/ # 官方源码,尽量少修改
├── custom_components/ # 自定义节点目录(核心扩展点)
│ ├── __init__.py
│ ├── internal_api.py # 内部业务API节点
│ └── vector_search.py # 私有向量库节点
├── custom_middleware/ # 自定义中间件(鉴权、日志等)
├── deploy/ # 部署配置文件
└── .env # 环境变量配置
4.2 核心扩展:自定义业务节点开发
LangFlow 的组件系统采用分层类结构,所有自定义节点都继承自 Component 基类,通过类属性声明展示信息,通过 Input/Output 类声明参数与端口,最终实现 build 方法编写核心逻辑。其生命周期遵循"实例化→参数映射→执行构建→返回结果"的标准流程,前端根据后端声明自动渲染交互界面。
示例:企业内部业务 API 调用节点
from langflow import Component
from langflow.io import TextInput, DropdownInput, Output
from langflow.schema import Data
import requests
import os
import logging
logger = logging.getLogger(__name__)
class InternalApiNode(Component):
display_name = "内部业务API调用"
description = "调用公司内部业务系统接口,自动注入统一鉴权"
icon = "building"
category = "企业自定义"
api_path = DropdownInput(
name="api_path",
display_name="接口类型",
options=["/user/query", "/order/search", "/contract/parse"],
default="/user/query",
required=True,
info="选择需要调用的内部业务接口"
)
input_text = TextInput(
name="input_text",
display_name="输入参数文本",
required=True,
info="传递给接口的业务参数"
)
output_result = Output(
name="result",
display_name="接口返回结果",
method="build"
)
def build(self) -> Data:
base_url = os.getenv("INTERNAL_API_BASE", "https://api.your-company.com")
full_url = f"{base_url}{self.api_path}"
token = os.getenv("INTERNAL_API_TOKEN", "")
headers = {"Authorization": f"Bearer {token}"}
try:
resp = requests.post(
full_url,
json={"text": self.input_text},
headers=headers,
timeout=10
)
resp.raise_for_status()
result = resp.json()
return Data(text=str(result), data=result)
except Exception as e:
logger.error(f"内部API调用失败: {str(e)}")
return Data(text=f"接口调用失败:{str(e)}", data={"error": str(e)})
注册加载自定义节点
通过环境变量指定组件目录,LangFlow 启动时会自动扫描加载,完全不需要修改官方源码:
export LANGFLOW_COMPONENTS_PATH="./custom_components"
langflow run --dev
启动后刷新前端页面,左侧组件面板会出现「企业自定义」分组,拖拽即可使用。
进阶:私有向量库检索节点
from langflow import Component
from langflow.io import TextInput, IntInput, Output
from langflow.schema import Data
from pymilvus import connections, Collection
import os
class PrivateMilvusSearch(Component):
display_name = "私有向量库检索"
description = "调用公司内部Milvus向量知识库"
icon = "database"
category = "企业自定义"
collection_name = TextInput(name="collection_name", display_name="知识库集合名", required=True)
query_text = TextInput(name="query_text", display_name="检索文本", required=True)
top_k = IntInput(name="top_k", display_name="返回条数", default=5, required=True)
output = Output(name="results", display_name="检索结果", method="build")
def build(self) -> list[Data]:
connections.connect(
alias="default",
host=os.getenv("MILVUS_HOST"),
port=os.getenv("MILVUS_PORT", "19530"),
user=os.getenv("MILVUS_USER"),
password=os.getenv("MILVUS_PASSWORD")
)
embedding = self._get_internal_embedding(self.query_text)
collection = Collection(self.collection_name)
search_params = {"metric_type": "IP", "params": {"nprobe": 10}}
results = collection.search(
data=[embedding],
anns_field="vector",
param=search_params,
limit=self.top_k,
output_fields=["content", "metadata"]
)
return [
Data(text=hit.entity.get("content"), metadata=hit.entity.get("metadata"))
for hit in results[0]
]
def _get_internal_embedding(self, text: str) -> list[float]:
pass
4.3 系统集成:对接自有用户体系与权限隔离
轻量方案:JWT 统一身份认证
适合内部系统对接,保留 LangFlow 核心能力,仅在 API 层增加鉴权拦截。
- 新增自定义鉴权中间件(
custom_middleware/auth.py):
from starlette.middleware.base import BaseHTTPMiddleware
from starlette.requests import Request
from starlette.responses import JSONResponse
import jwt
import os
class CustomJWTAuthMiddleware(BaseHTTPMiddleware):
async def dispatch(self, request: Request, call_next):
public_paths = ["/", "/login", "/static", "/health"]
if any(request.url.path.startswith(p) for p in public_paths):
return await call_next(request)
auth_header = request.headers.get("Authorization", "")
if not auth_header.startswith("Bearer "):
return JSONResponse(status_code=401, content={"detail": "未授权访问"})
token = auth_header.split(" ")[1]
try:
payload = jwt.decode(token, os.getenv("JWT_SECRET"), algorithms=["HS256"])
request.state.user_id = payload["user_id"]
request.state.username = payload["username"]
except Exception:
return JSONResponse(status_code=401, content={"detail": "Token无效或已过期"})
return await call_next(request)
- 注册中间件(在 LangFlow 的 FastAPI 应用初始化文件中注册,这是唯一需要修改官方源码的地方):
from custom_middleware.auth import CustomJWTAuthMiddleware
app.add_middleware(CustomJWTAuthMiddleware)
-
配套配置:设置环境变量
LANGFLOW_AUTH=false关闭原生登录;前端改造登录页重定向到企业统一登录地址。 -
数据权限隔离:修改工作流保存、查询的接口逻辑,自动根据请求上下文中的
user_id追加过滤条件。
进阶方案:多租户与 RBAC 权限
- 在工作流、数据流等核心表增加
tenant_id字段,所有查询强制租户隔离; - 新增角色权限表,定义管理员、开发者、查看者等角色;
- 增加工作流版本管理、发布审批等企业级流程。
4.4 白标定制与生产级部署
前端品牌定制
无需修改核心代码,通过静态资源替换和环境变量即可完成白标改造:
- 系统名称:设置前端环境变量
VITE_APP_NAME; - Logo 与图标:替换
src/frontend/public目录下的 logo、favicon 等静态资源; - 主题色:修改前端全局 CSS 变量,适配企业 VI 规范。
生产环境配置
-
数据库切换:生产环境建议切换到 PostgreSQL:
export LANGFLOW_DATABASE_URL="postgresql://user:password@db-host:5432/langflow_db" -
容器化部署:
FROM langflowai/langflow:latest COPY ./custom_components /app/custom_components COPY ./custom_middleware /app/custom_middleware ENV LANGFLOW_COMPONENTS_PATH="/app/custom_components" ENV LANGFLOW_DATABASE_URL="postgresql://user:password@db:5432/langflow" EXPOSE 7860 CMD ["langflow", "run", "--host", "0.0.0.0", "--port", "7860"]
五、二次开发最佳实践与避坑指南
5.1 代码维护最佳实践
-
最小侵入原则:尽可能通过自定义组件、中间件、环境变量实现定制,不修改官方核心执行逻辑。若必须修改,做好标记并单独维护补丁,便于后续版本合并。
-
自定义代码独立封装:当自定义节点数量较多时,可封装为独立 Python 包,通过 pip 安装注入,进一步降低与官方源码的耦合度。
-
版本同步策略:定期跟踪官方稳定版更新,每 1-2 个版本同步一次主干代码,避免分叉过远导致无法享受官方新功能与安全修复。
5.2 常见坑点与解决方案
-
节点异常导致整体工作流崩溃:所有自定义节点必须做好异常捕获和超时控制,标准化错误输出格式,避免单个节点故障导致整条流程中断。
-
敏感信息泄露:所有 API 密钥、数据库连接串、内部地址必须通过环境变量或配置中心注入,绝对禁止硬编码在节点代码中,也不要暴露在前端配置面板中。
-
大工作流执行性能问题:复杂多节点工作流建议开启异步执行模式,对重复调用的节点结果进行缓存;对外部 API 调用设置合理的超时与重试机制。
-
权限隔离不彻底:数据权限过滤必须在数据库查询层统一实现,不要依赖单个接口的手动过滤,避免遗漏导致数据越权访问。
六、最终选型建议:推荐技术栈组合
基于以上全景分析,推荐以下分层技术栈:
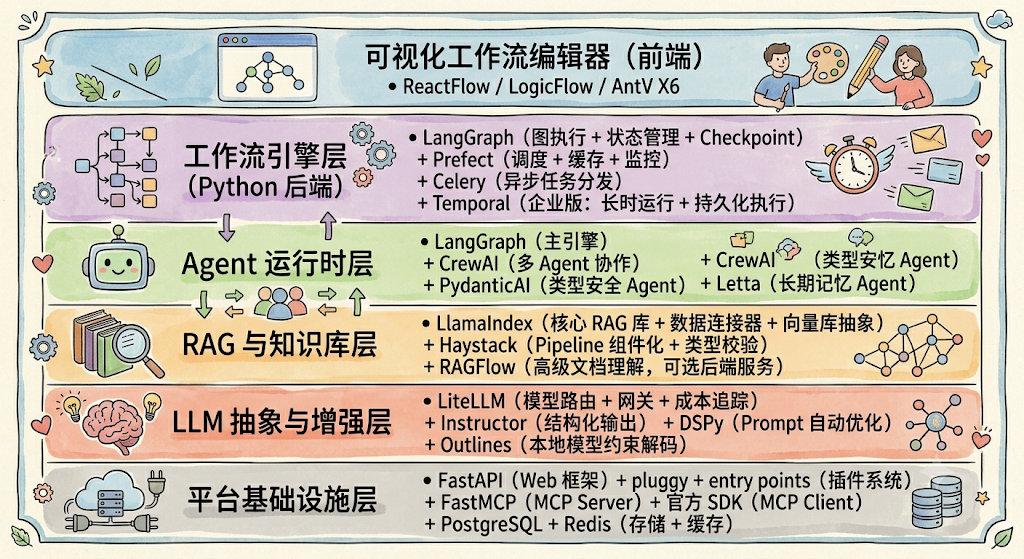
按场景的选型建议:
-
快速验证、内部工具场景:优先选择 LangFlow 二次开发,1-2 周即可落地专属编排平台,Python 技术栈无缝衔接,扩展成本最低。
-
企业级一站式 AI 平台:基于 Dify 进行二次开发,复用成熟的知识库、对话应用、权限体系,聚焦业务功能定制。
-
长期独立产品、深度定制需求:采用"前端 ReactFlow 画布 + 后端 FastAPI + LangGraph"的拼装路线,掌握核心架构自主权。
-
文档 RAG 核心场景:以 RAGFlow 为底座扩展工作流能力,最大化发挥文档解析优势。
-
混合路线:Fork Dify 的前端(Next.js + React Flow 编辑器)+ 用 LangGraph + FastAPI + LlamaIndex 重写后端核心引擎,兼顾前端快速启动和后端架构自主可控。
AI 编排平台的建设不是一蹴而就的,建议团队遵循"先验证、再扩展、后自研"的路径,从开源底座二次开发起步,快速验证业务价值,再根据发展阶段逐步深化定制,平衡落地效率与长期技术自主性。
评论区