



本文基于当前最新的 Apache Spark 4.0 编写,覆盖从环境搭建、核心概念、各模块编程到性能调优与实战项目的完整学习路径。所有代码示例均可在本地或集群环境中运行。

一、Spark 概述
1.1 什么是 Spark
Apache Spark 是一个开源的统一分析引擎,用于大规模数据处理。它由加州大学伯克利分校的 AMPLab 于 2009 年开发,2013 年捐赠给 Apache 软件基金会,如今已成为大数据领域最活跃的项目之一。
Spark 的核心价值在于"统一"二字:同一套引擎、同一套 API,既能做批处理,也能做流处理、机器学习和图计算。这意味着开发者不需要为不同场景学习多套工具,数据也无需在不同系统间来回搬运。
1.2 Spark 的核心优势
速度。 Spark 基于内存计算,通过 DAG(有向无环图)执行引擎将作业拆分为可并行的任务。对于某些工作负载,Spark 的速度可达 Hadoop MapReduce 的 100 倍以上。
易用性。 Spark 提供 Java、Scala、Python(PySpark)、R 和 SQL 多种语言的 API。以 Python 为例,几十行代码就能完成原本需要数百行 MapReduce 才能实现的逻辑。
统一性。 Spark 内置了 SQL、Streaming、MLlib、GraphX 等模块,无需集成多个独立系统。
运行广泛。 Spark 可运行在 Hadoop YARN、Apache Mesos、Kubernetes 上,也能以独立模式运行,数据可来自 HDFS、HBase、Cassandra、Kafka 等多种存储。
1.3 Spark 生态模块一览
| 模块 | 功能定位 | 典型场景 |
|---|---|---|
| Spark Core | 底层引擎,提供任务调度、内存管理、容错恢复 | 所有模块的基础 |
| Spark SQL | 结构化数据处理,支持 SQL 查询 | 数据仓库、ETL、报表分析 |
| Structured Streaming | 流式处理,基于微批或连续处理 | 实时日志分析、监控告警 |
| MLlib | 分布式机器学习库 | 推荐系统、分类回归、聚类 |
| GraphX | 图计算库 | 社交网络分析、PageRank |
二、核心概念与运行架构
2.1 运行架构总览
Spark 应用程序采用"Driver - Executor"的主从架构。理解这套架构是后续调优和排错的基础。
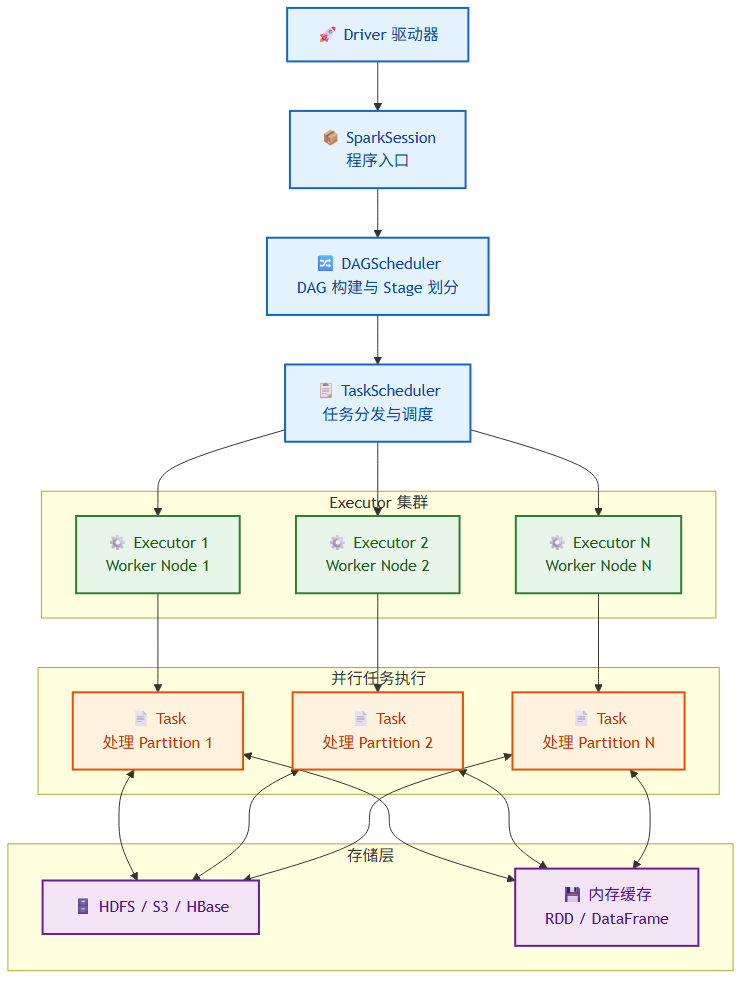
Driver 是应用程序的主进程,负责解析用户代码、构建 DAG、将作业拆分为 Stage 和 Task,并把任务分发到各个 Executor。它还维护着 SparkSession/SparkContext,是程序与集群交互的入口。
Executor 是运行在工作节点上的 JVM 进程,负责执行具体的 Task,并把计算结果返回给 Driver。Executor 同时管理着分配给该应用的内存,用于缓存 RDD/DataFrame 的数据。
2.2 核心术语速查
| 术语 | 含义 |
|---|---|
| Application | 一个 Spark 应用程序,由一个 Driver 和若干 Executor 组成 |
| Job | 一个 Action 操作触发一个 Job |
| Stage | Job 根据 Shuffle 划分为多个 Stage,同一 Stage 内任务无依赖可并行 |
| Task | 最小执行单元,一个 Task 处理一个 Partition 的数据 |
| Partition | 数据分片,是并行度的基本单位 |
| Shuffle | 不同 Stage 间数据重新分布的过程,是性能瓶颈的重灾区 |
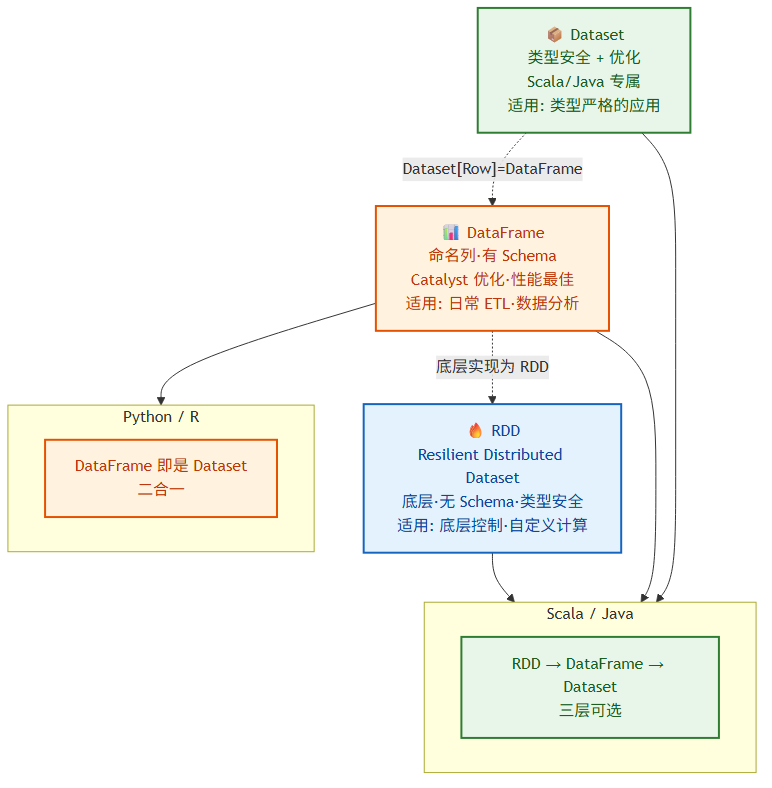
2.3 数据抽象:RDD、DataFrame、Dataset
Spark 提供了三种核心数据抽象,理解它们的差异决定了你能否写出高效的代码。
RDD(Resilient Distributed Dataset) 是 Spark 最底层的抽象,一个不可变、分区的分布式集合。它具有容错性——当某个分区的数据丢失时,Spark 可以根据血缘关系(Lineage)重新计算。RDD 没有结构信息,Spark 无法对其进行优化,适合需要对底层控制有精细要求的场景。
DataFrame 是以命名列组织的分布式数据集,概念上等同于关系数据库中的表。它拥有 Schema(结构信息),Spark 的 Catalyst 优化器可以基于 Schema 进行查询优化,因此大多数场景下性能优于 RDD。
Dataset 是 DataFrame 的类型化版本(在 Scala/Java 中),结合了 RDD 的类型安全和 DataFrame 的优化能力。在 Python 和 R 中,DataFrame 即是 Dataset。
三者关系可以简单理解为:RDD 是基础,DataFrame/Dataset 是上层封装,日常开发优先使用 DataFrame/Dataset。
三、环境搭建与快速入门
3.1 安装 Java 与 Spark
Spark 4.0 要求 JDK 17 及以上(推荐 JDK 17 或 21),并默认使用 Scala 2.13。这是与旧版本最大的环境差异,升级时务必注意。
以 Linux 环境为例,安装步骤如下:
# 1. 安装 JDK 17
sudo apt update
sudo apt install openjdk-17-jdk
java -version # 确认输出 17.x
# 2. 下载 Spark 4.0 预编译包(以 4.0.0 为例,with Hadoop 3)
wget https://archive.apache.org/dist/spark/spark-4.0.0/spark-4.0.0-bin-hadoop3.tgz
tar -xzf spark-4.0.0-bin-hadoop3.tgz
sudo mv spark-4.0.0-bin-hadoop3 /opt/spark
# 3. 配置环境变量
echo 'export SPARK_HOME=/opt/spark' >> ~/.bashrc
echo 'export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin' >> ~/.bashrc
source ~/.bashrc
# 4. 验证安装
spark-shell --version
3.2 安装 PySpark
对于 Python 用户,直接通过 pip 安装即可:
pip install pyspark==4.0.0
Spark 4.0 还提供了一个仅 1.5 MB 的轻量级 Python 客户端 pyspark-client,它通过 Spark Connect 协议连接到远程 Spark 服务,无需在本地安装完整的 Spark 环境:
pip install pyspark-client
3.3 第一个 Spark 程序
以下是一个经典的词频统计(WordCount)示例,用三种方式实现,帮助你直观感受 Spark 的编程模型。
PySpark 版本:
from pyspark.sql import SparkSession
# 创建 SparkSession(Spark 2.0+ 的统一入口)
spark = SparkSession.builder \
.appName("WordCount") \
.master("local[*]") \
.getOrCreate()
# 读取文本文件 -> 分词 -> 计数
counts = spark.read.text("README.md") \
.selectExpr("explode(split(value, ' ')) as word") \
.filter("word != ''") \
.groupBy("word") \
.count() \
.orderBy("count", ascending=False)
counts.show(20, truncate=False)
spark.stop()
Scala 版本(spark-shell 中直接运行):
val spark = SparkSession.builder().appName("WordCount").getOrCreate()
val counts = spark.read.textFile("README.md")
.flatMap(line => line.split(" "))
.filter(_ != "")
.groupBy("value")
.count()
.orderBy(desc("count"))
counts.show(20)
SQL 版本(spark-sql 交互式命令行):
-- 在 spark-sql 中注册临时视图后查询
CREATE OR REPLACE TEMP VIEW words AS
SELECT explode(split(value, ' ')) AS word FROM text_data;
SELECT word, COUNT(*) AS cnt
FROM words
WHERE word != ''
GROUP BY word
ORDER BY cnt DESC
LIMIT 20;
三种写法背后执行的是同一套引擎,最终都会被 Catalyst 优化器转换为物理执行计划。这正是 Spark"统一引擎"理念的体现。
3.4 交互式工具
Spark 提供了三个常用交互式入口:
spark-shell:Scala 交互环境,适合快速验证逻辑pyspark:Python 交互环境,适合数据探索spark-sql:SQL 交互命令行,适合熟悉 SQL 的用户
启动 spark-shell 后,会自动创建名为 spark 的 SparkSession 和名为 sc 的 SparkContext,可直接使用。
四、RDD 编程基础
虽然日常开发推荐使用 DataFrame,但 RDD 是理解 Spark 运行机制的基础。掌握 RDD 有助于你在遇到性能瓶颈时理解底层发生了什么。
4.1 创建 RDD
from pyspark import SparkContext
sc = SparkContext("local[*]", "RDDDemo")
# 方式一:从集合并行化创建
rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 方式二:从外部存储读取
rdd2 = sc.textFile("hdfs://localhost:9000/data/log.txt")
# 查看分区数
print(rdd1.getNumPartitions()) # local[*] 模式下默认为 CPU 核数
4.2 Transformation 与 Action
RDD 操作分为两类,这是理解 Spark 惰性求值的关键。
Transformation(转换) 创建一个新的 RDD,但不会立即执行,而是记录血缘关系。常见的转换操作包括 map、filter、flatMap、distinct、union、intersection、join 等。
Action(行动) 触发实际计算,将结果返回 Driver 或写入存储。常见的行动操作包括 collect、count、take、reduce、saveAsTextFile 等。
data = sc.parallelize(range(1, 11))
# 以下都是 Transformation,不会触发计算
evens = data.filter(lambda x: x % 2 == 0) # [2, 4, 6, 8, 10]
squared = evens.map(lambda x: x ** 2) # [4, 16, 36, 64, 100]
# Action 触发计算
print(squared.collect()) # [4, 16, 36, 64, 100]
print(squared.count()) # 5
print(squared.reduce(lambda a, b: a + b)) # 220
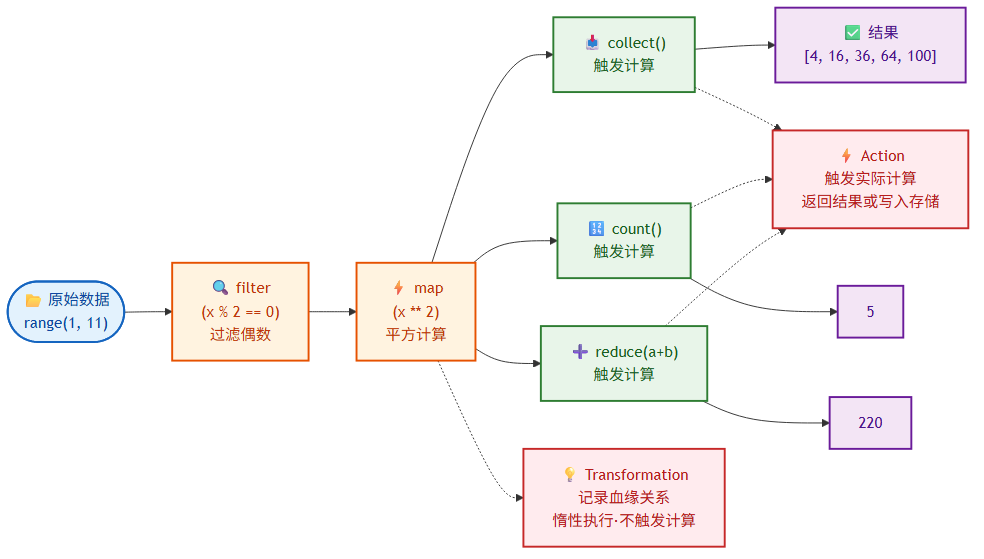
这种惰性求值机制让 Spark 能够看到整个计算链路后再优化,而不是逐条执行。理解这一点,就能明白为什么 collect() 之前似乎"什么都没发生"。
4.3 持久化与缓存
当某个 RDD 会被多次使用时,应当将其缓存到内存,避免重复计算。这是 Spark 性能优化的第一课。
rdd = sc.textFile("data/large_file.txt") \
.filter(lambda line: "error" in line.lower())
# 缓存到内存
rdd.cache() # 等价于 rdd.persist(StorageLevel.MEMORY_ONLY)
# 第一次使用:触发计算并缓存
error_count = rdd.count()
# 第二次使用:直接从内存读取,跳过重新读取文件和过滤
sample_errors = rdd.take(10)
常用的存储级别:
| 存储级别 | 说明 |
|---|---|
MEMORY_ONLY |
仅存内存,存不下则不缓存(默认) |
MEMORY_AND_DISK |
内存存不下时溢写到磁盘 |
MEMORY_ONLY_SER |
序列化后存内存,节省空间 |
DISK_ONLY |
仅存磁盘 |
缓存是"按需"使用的,用完应当手动释放:rdd.unpersist()。
4.4 共享变量
Spark 提供两种共享变量,用于解决"闭包数据传递"和"累加统计"问题。
广播变量 将只读数据高效地分发到所有节点,避免每个任务都携带一份副本,适合大表 join 小表的场景。
# 广播一份城市编码映射表
city_map = {1: "北京", 2: "上海", 3: "广州", 4: "深圳"}
broadcast_city = sc.broadcast(city_map)
rdd = sc.parallelize([(1, "张三"), (2, "李四"), (3, "王五")])
result = rdd.map(lambda x: (x[1], broadcast_city.value[x[0]]))
print(result.collect())
# [('张三', '北京'), ('李四', '上海'), ('王五', '广州')]
累加器 用于跨节点的聚合统计,只有 Driver 能读取最终值。
acc = sc.accumulator(0)
def count_error(line):
global acc
if "error" in line.lower():
acc += 1
sc.textFile("logs/app.log").foreach(count_error)
print(f"错误日志总数: {acc.value}")
五、DataFrame 与 Dataset
DataFrame 是日常开发中最常用的数据抽象,它结合了 RDD 的分布式特性和关系表的易用性。这一章是全文的重点。
5.1 创建 DataFrame
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DoubleType
spark = SparkSession.builder.appName("DFDemo").master("local[*]").getOrCreate()
# 方式一:从内部数据创建
df = spark.createDataFrame(
[("张三", 28, 8500.0), ("李四", 35, 12000.0), ("王五", 22, 6000.0)],
schema=["name", "age", "salary"]
)
# 方式二:指定 Schema 创建(生产环境推荐,避免类型推断出错)
schema = StructType([
StructField("name", StringType(), False),
StructField("age", IntegerType(), True),
StructField("salary", DoubleType(), True)
])
df2 = spark.createDataFrame(
[("张三", 28, 8500.0), ("李四", 35, 12000.0)],
schema=schema
)
# 方式三:从文件读取(最常用)
df_json = spark.read.json("data/users.json")
df_csv = spark.read.option("header", True).csv("data/users.csv")
df_parquet = spark.read.parquet("data/users.parquet") # 性能最佳
5.2 DataFrame 操作
DataFrame 操作有两条路径:DataFrame API 和 Spark SQL。两者等价,可以混用。
DataFrame API 风格:
from pyspark.sql.functions import col, avg, sum, max, count, when
result = df.filter(col("age") >= 25) \
.groupBy() \
.agg(
count("*").alias("total"),
avg("salary").alias("avg_salary"),
max("salary").alias("max_salary")
)
result.show()
Spark SQL 风格:
df.createOrReplaceTempView("employees")
result = spark.sql("""
SELECT COUNT(*) AS total, AVG(salary) AS avg_salary, MAX(salary) AS max_salary
FROM employees
WHERE age >= 25
""")
result.show()
两种写法生成的执行计划完全相同,选择哪种取决于团队习惯。SQL 风格对数据分析人员更友好,API 风格在构建复杂管道时更灵活。
5.3 常用操作速查
from pyspark.sql.functions import col, desc, expr, lit, concat
# 选择与过滤
df.select("name", "salary").show()
df.filter((col("age") > 25) & (col("salary") < 10000)).show()
# 排序与去重
df.orderBy(desc("salary")).show()
df.dropDuplicates(["name"]).show()
# 新增列
df = df.withColumn("bonus", col("salary") * 0.1)
df = df.withColumn("level", when(col("salary") > 10000, "高级").otherwise("普通"))
# 聚合
df.groupBy("level").agg(avg("salary").alias("avg_sal")).show()
# 连接
df_a.join(df_b, df_a.id == df_b.id, "inner").show() # 内连接
df_a.join(df_b, df_a.id == df_b.id, "left").show() # 左连接
df_a.join(df_b, df_a.id == df_b.id, "left_anti").show() # 反连接:在 A 不在 B
# 窗口函数
from pyspark.sql.window import Window
w = Window.partitionBy("department").orderBy(desc("salary"))
df.withColumn("rank", row_number().over(w)).show()
5.4 数据读写
Spark 支持多种数据源,读写时可以指定格式、分区、压缩等选项。
# 读取 JSON(支持自动推断 Schema)
df = spark.read.option("multiline", True).json("data/nested.json")
# 读取 CSV(推荐显式指定 Schema 和选项)
df = spark.read \
.option("header", True) \
.option("inferSchema", True) \
.option("sep", ",") \
.csv("data/sales.csv")
# 读取 Parquet(列式存储,性能最佳)
df = spark.read.parquet("data/sales.parquet")
# 写入时按列分区
df.write \
.mode("overwrite") \
.partitionBy("year", "month") \
.parquet("output/sales_partitioned")
# 写入时指定压缩
df.write \
.mode("append") \
.option("compression", "snappy") \
.parquet("output/sales_compressed")
Parquet 和 ORC 是列式存储格式,配合谓词下推可以跳过不必要的文件和列读取,是数据仓库的首选格式。
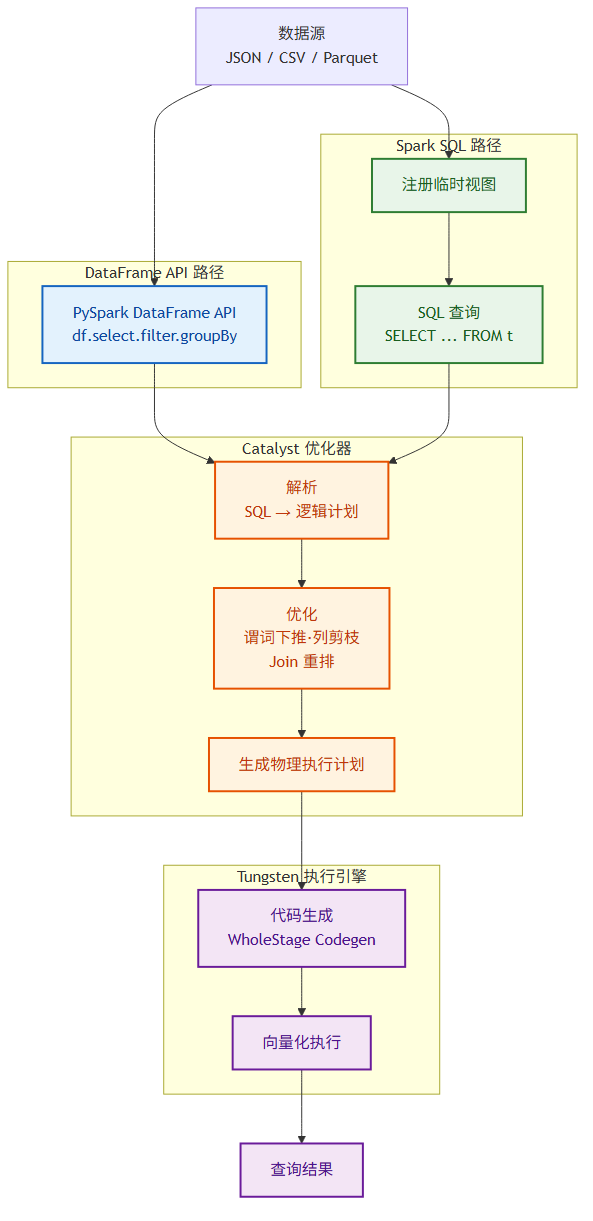
六、Spark SQL 详解
Spark SQL 是 Spark 中使用最频繁的模块。Spark 4.0 在 SQL 兼容性上做了大幅增强,许多原本需要 UDF 的逻辑现在可以用标准 SQL 完成。
6.1 Catalog 与表管理
Spark 通过 Catalog 管理数据库、表、视图和函数的元数据。
-- 创建数据库
CREATE DATABASE IF NOT EXISTS analytics
LOCATION '/warehouse/analytics';
-- 创建表
CREATE TABLE IF NOT EXISTS analytics.sales (
id BIGINT,
product_name STRING,
amount DECIMAL(10, 2),
sale_date DATE
)
PARTITIONED BY (sale_date)
STORED AS PARQUET;
-- 查看表结构(Spark 4.0 支持以 JSON 格式描述表)
DESCRIBE TABLE EXTENDED analytics.sales;
6.2 常用 SQL 查询
-- 基本聚合
SELECT
product_name,
COUNT(*) AS order_cnt,
SUM(amount) AS total_amount,
AVG(amount) AS avg_amount
FROM analytics.sales
WHERE sale_date >= '2026-01-01'
GROUP BY product_name
HAVING SUM(amount) > 10000
ORDER BY total_amount DESC;
-- 窗口函数
SELECT
product_name,
sale_date,
amount,
ROW_NUMBER() OVER (PARTITION BY product_name ORDER BY amount DESC) AS rn,
SUM(amount) OVER (PARTITION BY product_name) AS product_total
FROM analytics.sales;
-- 多表连接
SELECT s.product_name, s.amount, c.category_name
FROM sales s
JOIN product_catalog c ON s.product_name = c.name
WHERE c.category_name = '电子产品';
6.3 SQL 与 DataFrame 混用
实际开发中,SQL 和 DataFrame API 混用是很常见的做法。DataFrame 可以注册为临时视图供 SQL 查询,SQL 查询结果也可以转为 DataFrame 继续处理。
# DataFrame 注册为视图
df.createOrReplaceTempView("temp_employees")
# 用 SQL 查询,结果仍是 DataFrame
high_salary = spark.sql("SELECT * FROM temp_employees WHERE salary > 10000")
# 继续用 API 处理
high_salary.groupBy("department").count().show()
6.4 Spark 4.0 的 SQL 增强
Spark 4.0 默认开启 ANSI SQL 模式,这意味着诸如除零、数值溢出、非法日期等操作会直接抛出错误而非静默返回 NULL,有助于尽早发现数据质量问题。从旧版本迁移时,部分依赖"静默容错"的代码可能需要调整。
新增的 会话变量 允许在 SQL 中定义和使用变量,减少对 UDF 的依赖:
-- 定义会话变量
DECLARE report_date DATE DEFAULT CURRENT_DATE;
DECLARE threshold DOUBLE DEFAULT 10000.0;
-- 在查询中使用
SELECT product_name, SUM(amount) AS total
FROM sales
WHERE sale_date = report_date
GROUP BY product_name
HAVING SUM(amount) > threshold;
新增的 SQL 用户定义函数 让你可以在纯 SQL 中定义可复用的函数,无需切换到 Python 或 Scala:
-- 用 SQL 定义函数
CREATE FUNCTION calc_discount(price DOUBLE, rate DOUBLE)
RETURNS DOUBLE
RETURN price * (1 - rate);
-- 使用函数
SELECT product_name, calc_discount(amount, 0.15) AS discounted FROM sales;
七、结构化流处理 Structured Streaming
Structured Streaming 是 Spark 的流处理引擎,它把流数据视为一个不断增长的 DataFrame,用与批处理相同的 API 来处理流。这种"批流统一"的设计大幅降低了学习成本。
7.1 核心概念
Structured Streaming 将流入的数据视为无界 DataFrame,每来一批新数据,就把它"追加"到现有 DataFrame 上,然后增量地执行查询。输出模式有三种:
| 输出模式 | 说明 | 适用场景 |
|---|---|---|
append |
只输出新增的行 | 无聚合查询、写入 Kafka |
update |
只输出有变更的行 | 有聚合、无需完整结果 |
complete |
输出完整结果表 | 结果集小、需全量展示 |
7.2 读取 Kafka 流并统计
以下示例从 Kafka 读取日志流,按错误级别实时统计数量,并写入控制台。这是最常见的流处理范式。
from pyspark.sql.functions import col, from_json, window
from pyspark.sql.types import StructType, StructField, StringType, TimestampType
spark = SparkSession.builder.appName("StreamingDemo").getOrCreate()
# 定义日志 Schema
log_schema = StructType([
StructField("timestamp", TimestampType()),
StructField("level", StringType()),
StructField("message", StringType())
])
# 从 Kafka 读取流
stream = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "app-logs") \
.load()
# 解析 JSON 并按窗口聚合
parsed = stream.selectExpr("CAST(value AS STRING) as json") \
.select(from_json(col("json"), log_schema).alias("log")) \
.select("log.*")
windowed = parsed \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
window(col("timestamp"), "5 minutes"),
col("level")
) \
.count()
# 写入控制台
query = windowed.writeStream \
.outputMode("update") \
.format("console") \
.option("truncate", False) \
.trigger(processingTime="30 seconds") \
.start()
query.awaitTermination()
withWatermark 告诉引擎:超过这个时间的数据可以丢弃,防止状态无限增长。这是处理迟到数据的关键机制。
7.3 输出到多种 Sink
# 写入文件(仅支持 append 模式)
query = result.writeStream \
.format("parquet") \
.option("path", "output/stream") \
.option("checkpointLocation", "checkpoint/stream") \
.outputMode("append") \
.start()
# 写入 Kafka
query = result.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("topic", "aggregated-results") \
.option("checkpointLocation", "checkpoint/kafka") \
.start()
# Foreach 写入外部系统(如 Redis、MySQL)
def process_row(row):
# 自定义写入逻辑
pass
query = result.writeStream \
.foreachBatch(lambda df, batch_id: df.foreach(process_row)) \
.option("checkpointLocation", "checkpoint/foreach") \
.start()
Checkpoint 是流处理的命脉。 它记录了流的进度和状态,当作业失败重启时,能从上次的位置继续。生产环境必须配置可靠的检查点路径(通常是 HDFS 或对象存储)。
7.4 Spark 4.0 的状态管理增强
Spark 4.0 引入了 Arbitrary State API v2(transformWithState),提供了更灵活的状态管理能力。它支持状态 TTL(自动过期)、确定性定时器、以及在不重启作业的情况下演进状态 Schema。
from pyspark.sql.functions import col
from pyspark.sql.streaming.state import StateValueProcessor
class SessionAggregator(StateValueProcessor):
def process(self, key, row, state):
current = state.getValue() or 0
new_value = current + row["amount"]
state.update(new_value)
# 设置 TTL,10 分钟后状态自动清理
state.setTimeoutDuration("10 minutes")
result = stream.groupByKey().transformWithState(
SessionAggregator(),
outputMode="update",
timeoutConf="ProcessingTimeTimeout"
)
同时新增的 状态数据源 允许你像查 DataFrame 一样查询正在运行的流作业的状态,方便调试和监控。
八、Spark MLlib 机器学习
MLlib 是 Spark 的分布式机器学习库,适合在 TB 级数据上训练模型。它提供了特征工程、分类回归、聚类、协同过滤等常用算法。
8.1 ML Pipeline 工作流
MLlib 推荐使用 Pipeline API 构建机器学习工作流,它把数据处理的各个阶段(特征转换、特征提取、模型训练)组装成一条管道,便于复用和调参。
from pyspark.ml import Pipeline
from pyspark.ml.feature import Tokenizer, StopWordsRemover, HashingTF, IDF, StringIndexer
from pyspark.ml.classification import LogisticRegression
# 准备数据
training = spark.createDataFrame([
(0, "Spark 性能很好 推荐使用", 1.0),
(1, "这个产品太差了 不推荐", 0.0),
(2, "Spark 集群部署简单", 1.0),
(3, "速度太慢 体验很差", 0.0),
], ["id", "text", "label"])
# 构建处理阶段
tokenizer = Tokenizer(inputCol="text", outputCol="words")
remover = StopWordsRemover(inputCol="words", outputCol="filtered")
hashingTF = HashingTF(inputCol="filtered", outputCol="rawFeatures", numFeatures=10000)
idf = IDF(inputCol="rawFeatures", outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
# 组装 Pipeline
pipeline = Pipeline(stages=[tokenizer, remover, hashingTF, idf, lr])
# 训练
model = pipeline.fit(training)
# 预测
test = spark.createDataFrame([
(4, "Spark 真的很好用 速度快"),
(5, "太慢了 不行"),
], ["id", "text"])
prediction = model.transform(test)
prediction.select("text", "prediction", "probability").show(truncate=False)
8.2 模型评估与调参
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
# 评估
evaluator = BinaryClassificationEvaluator(
rawPredictionCol="rawPrediction",
labelCol="label",
metricName="areaUnderROC"
)
auc = evaluator.evaluate(prediction)
print(f"AUC: {auc:.4f}")
# 网格搜索调参
paramGrid = ParamGridBuilder() \
.addGrid(hashingTF.numFeatures, [1000, 5000, 10000]) \
.addGrid(lr.regParam, [0.01, 0.1, 0.5]) \
.build()
cv = CrossValidator(
estimator=pipeline,
estimatorParamMaps=paramGrid,
evaluator=evaluator,
numFolds=5
)
cvModel = cv.fit(training)
bestModel = cvModel.bestModel
8.3 常用算法速查
| 任务类型 | 推荐算法 | 典型场景 |
|---|---|---|
| 二分类 | LogisticRegression、GBTClassifier | 风控、点击率预测 |
| 多分类 | RandomForestClassifier、NaiveBayes | 文本分类、图像分类 |
| 回归 | LinearRegression、GBTRegressor | 房价预测、销量预测 |
| 聚类 | KMeans、BisectingKMeans | 用户分群、异常检测 |
| 协同过滤 | ALS | 推荐系统 |
| 特征工程 | PCA、Word2Vec、OneHotEncoder | 降维、向量化 |
MLlib 的优势在于分布式训练——当数据量超过单机内存时,它能横向扩展到整个集群,这是 scikit-learn 等单机库无法做到的。
九、Spark 4.0 新特性深度解析
Spark 4.0 是一次重要的大版本升级,带来了架构层面的变化和大量开发者体验改进。本章梳理最值得关注的新特性。
9.1 VARIANT 数据类型
Spark 4.0 原生支持 VARIANT 类型,专门用于处理 JSON、Avro 等半结构化数据。相比以往用字符串存储 JSON 再解析的方式,VARIANT 在存储和查询上都更高效。
-- 创建含 VARIANT 列的表
CREATE TABLE events (
id BIGINT,
payload VARIANT
) USING PARQUET;
-- 插入 JSON 数据(自动转为 VARIANT)
INSERT INTO events VALUES
(1, parse_json('{"user":"alice","action":"click","amount":99.5}'));
-- 直接查询半结构化字段,无需预定义 Schema
SELECT
id,
payload:user::STRING AS user_name,
payload:action::STRING AS action,
payload:amount::DOUBLE AS amount
FROM events;
-- 动态提取未知字段
SELECT payload:*.amount FROM events;
9.2 ANSI SQL 模式默认开启
Spark 4.0 默认启用 ANSI 模式,这是重要的 Breaking Change。在 ANSI 模式下,以下行为发生变化:
- 除零操作抛出异常,而非返回 NULL
- 数值溢出抛出异常,而非回绕
- 非法日期转换抛出异常
如果旧代码依赖静默容错,可以通过 spark.sql.ansi.enabled=false 临时关闭,但长期建议适配 ANSI 行为,以提升数据质量。
9.3 Spark Connect 客户端架构
Spark Connect 是 Spark 4.0 重点推进的客户端-服务器架构。它将 Spark 的"客户端库"与"执行引擎"解耦,带来几个好处:
- 轻量级客户端,无需在本地安装完整 Spark
- 支持多语言客户端(Python、Go、Swift、Java)
- 客户端与集群版本解耦,降低升级摩擦
# 使用轻量级 Python 客户端连接远程 Spark
from pyspark.sql.connect import SparkSession
spark = SparkSession.builder \
.remote("sc://my-spark-server:15002") \
.getOrCreate()
# 之后的 API 用法与本地完全一致
df = spark.read.parquet("hdfs://namenode/data/sales")
df.groupBy("product").sum("amount").show()
9.4 Python 数据源 API
Spark 4.0 提供了全新的 Python 数据源 API,开发者可以用纯 Python 编写自定义数据源连接器,无需编写 Scala/Java 代码。这对连接企业内部系统、自研存储特别有用。
from pyspark.sql.datasource import DataSource, DataSourceReader
class MyCustomSource(DataSource):
@classmethod
def reader(cls, schema):
return MyCustomReader(schema)
class MyCustomReader(DataSourceReader):
def __init__(self, schema):
self.schema = schema
def read(self, partition):
# 自定义读取逻辑,返回数据行
yield (1, "alice"), (2, "bob")
# 注册并使用
spark.dataSource.register(MyCustomSource, "my_source")
df = spark.read.format("my_source").load()
9.5 PySpark 原生绘图 API
Spark 4.0 为 PySpark 引入了原生绘图 API,可以直接对 DataFrame 绘图,无需将数据 collect 到本地再用 matplotlib 绘制。对于大数据集,这避免了 Driver 内存溢出的风险。
# 直接在分布式 DataFrame 上绘图
df = spark.read.parquet("data/sales")
plot = df.groupBy("category").sum("amount").plot.bar(x="category", y="sum(amount)")
plot.show()
9.6 其他重要变更
- Java 17 默认,支持 Java 21:弃用 JDK 8/11
- Scala 2.13 默认:弃用 Scala 2.12
- 内置 XML 数据源:无需额外依赖即可读写 XML
- Spark Kubernetes Operator:更原生的 K8s 集成
- 结构化日志:日志输出为结构化格式,便于采集分析
- SQL 管道语法:支持
|>管道操作符链式 SQL
十、性能调优实战
性能问题是 Spark 开发中最常遇到的挑战。本章按照"先诊断、后优化"的顺序,介绍实战中最有效的调优手段。
10.1 利用 Spark UI 诊断
Spark UI(默认 http://<driver>:4040)是性能调优的第一工具。重点关注的页面:
- Stages 页面:查看每个 Stage 的任务数、耗时、Shuffle 读写量。耗时极不均衡的任务(straggler)通常是数据倾斜的信号。
- SQL 页面:查看物理执行计划,定位 Shuffle、Broadcast、Scan 的开销。
- Storage 页面:查看缓存的使用率和内存命中率。
10.2 数据倾斜处理
数据倾斜是最常见的性能问题,表现为少数任务耗时远超其他任务。本质是某些 Key 的数据量远超平均值。
方案一:广播 join。 如果一张表足够小(默认 10MB 以内),可以广播到所有 Executor,避免 Shuffle。
# 自动广播(小于 spark.sql.autoBroadcastJoinThreshold 的表会自动广播)
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 50 * 1024 * 1024) # 50MB
# 手动指定广播
from pyspark.sql.functions import broadcast
big_df.join(broadcast(small_df), "id").show()
方案二:加盐打散。 对倾斜 Key 加随机前缀,分散到多个分区处理后再还原。
from pyspark.sql.functions import concat, lit, rand, split, col
# 给大表的倾斜 key 加盐
salted_big = big_df.withColumn("salted_id",
concat(col("id"), lit("_"), (rand() * 10).cast("int")))
# 给小表扩展 10 倍并对应加盐
from pyspark.sql.functions import explode, array
small_exploded = small_df.withColumn("salt",
explode(array([lit(i) for i in range(10)]))) \
.withColumn("salted_id", concat(col("id"), lit("_"), col("salt")))
# 用加盐 key join
result = salted_big.join(small_exploded, "salted_id")
方案三:开启自适应查询执行(AQE)。 Spark 3.0+ 的 AQE 能在运行时自动处理倾斜。
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", "true")
10.3 资源与并行度调优
# 分区数直接影响并行度,通常建议每个分区 128MB 左右数据
spark.conf.set("spark.sql.shuffle.partitions", 200) # 默认 200,按集群规模调整
# 读取时指定分区数
df = spark.read.option("maxPartitions", 100).parquet("data/large")
# 处理后重分区
df = df.repartition(200, "partition_key") # 按 key 重分布
df = df.coalesce(10) # 合并分区(避免 Shuffle,用于写小文件场景)
# Executor 内存与核心配置
spark = SparkSession.builder \
.config("spark.executor.memory", "8g") \
.config("spark.executor.cores", 4) \
.config("spark.executor.instances", 20) \
.getOrCreate()
10.4 缓存策略
不是所有数据都该缓存,缓存会占用宝贵的内存资源。判断标准是:该 DataFrame 是否会被多次使用,且计算成本是否高于缓存成本。
# 明确指定存储级别(生产环境推荐 MEMORY_AND_DISK)
from pyspark.sql import StorageLevel
df.persist(StorageLevel.MEMORY_AND_DISK)
# 查看缓存情况
print(spark.catalog.cacheTablesExist()) # 检查表是否缓存
# 用完及时释放
df.unpersist()
10.5 文件格式与压缩
# 使用列式存储 + 压缩,读写性能最优
spark.conf.set("spark.sql.parquet.compression.codec", "snappy") # 读写快
spark.conf.set("spark.sql.parquet.compression.codec", "zstd") # 压缩比高
# 避免小文件问题:写入前合并分区
df.coalesce(1).write.parquet("output/single_file") # 单文件(慎用,丢失并行度)
df.repartition("key").write.parquet("output/by_key") # 按 key 分文件
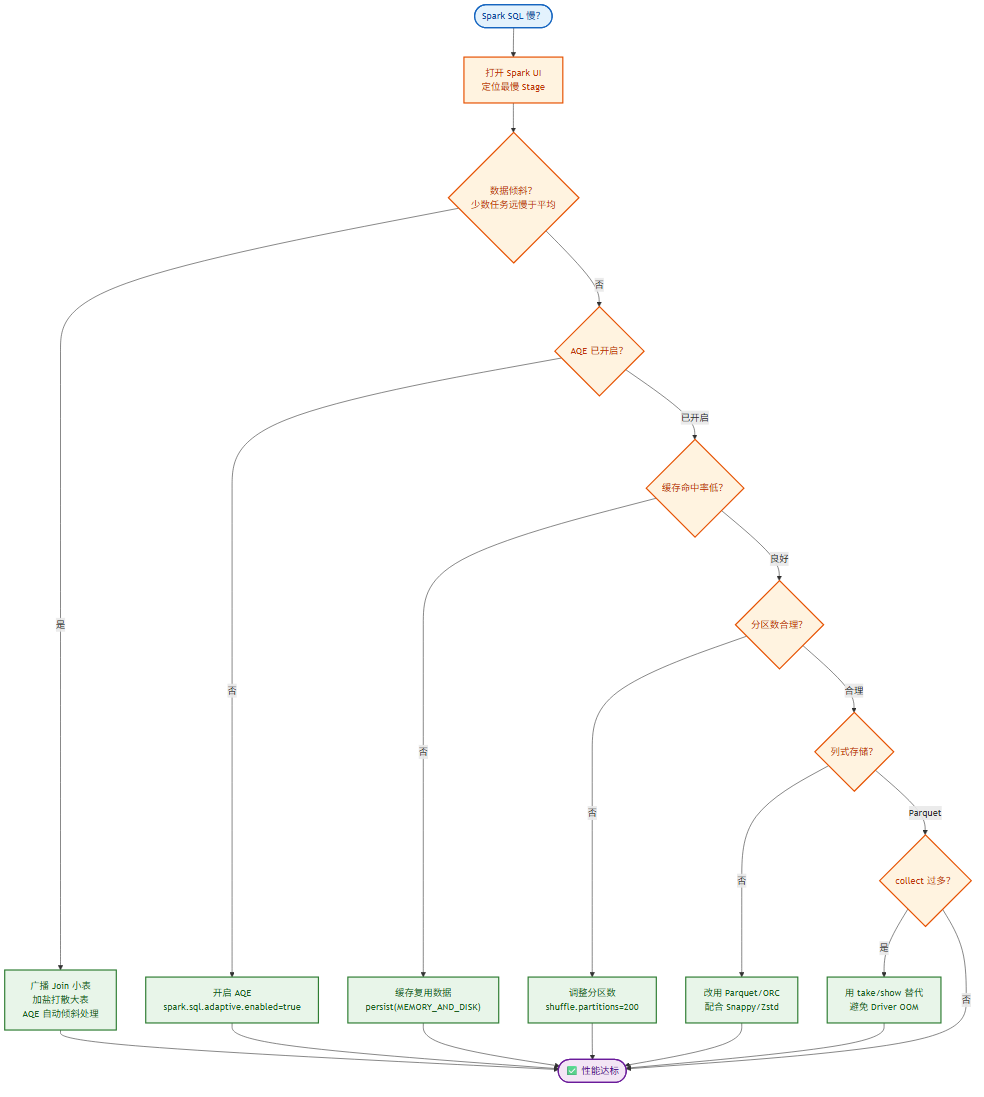
10.6 调优清单
面对性能问题时,按以下顺序排查通常最高效:
- 打开 Spark UI,定位最慢的 Stage
- 检查是否存在数据倾斜(任务耗时分布)
- 确认是否开启了 AQE
- 检查是否对重复使用的 DataFrame 做了缓存
- 检查分区数是否合理(过少导致并行度不足,过多导致调度开销)
- 确认使用了列式存储格式(Parquet/ORC)
- 检查是否可以用广播 join 替代 Shuffle join
- 检查是否触发了不必要的
collect()把数据拉到 Driver
十一、部署与集群管理
11.1 部署模式对比
| 模式 | 说明 | 适用场景 |
|---|---|---|
| Local | 单机多线程模拟集群 | 开发调试 |
| Standalone | Spark 自带的集群管理器 | 小规模生产 |
| YARN | 运行在 Hadoop YARN 上 | 已有 Hadoop 集群 |
| Kubernetes | 运行在 K8s 上 | 云原生环境 |
11.2 提交作业
使用 spark-submit 提交作业,核心参数如下:
spark-submit \
--master yarn \
--deploy-mode cluster \
--name SalesAnalytics \
--executor-memory 8g \
--executor-cores 4 \
--num-executors 20 \
--driver-memory 4g \
--conf spark.sql.adaptive.enabled=true \
--conf spark.sql.shuffle.partitions=400 \
--packages org.apache.spark:spark-sql-kafka-0-10_2.13:4.0.0 \
/path/to/your_app.py
关键参数说明:
--master:集群管理器地址(yarn、k8s://<api-server>、spark://<host>:7077)--deploy-mode:client(Driver 在提交机器)或cluster(Driver 在集群内,生产推荐)--executor-memory/--executor-cores:单个 Executor 的资源--num-executors:Executor 数量--packages:额外依赖的 Maven 坐标
11.3 Kubernetes 部署
Spark 4.0 对 K8s 支持做了显著增强,并引入了 Spark Kubernetes Operator,提供了更原生的 K8s 体验。
# 提交到 K8s
spark-submit \
--master k8s://https://<k8s-api-server>:6443 \
--deploy-mode cluster \
--name spark-on-k8s \
--conf spark.kubernetes.container.image=apache/spark:v4.0.0 \
--conf spark.kubernetes.namespace=spark \
--conf spark.executor.instances=10 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \
local:///opt/spark/examples/jars/spark-examples.jar
使用 Operator 的方式更声明式,适合与 GitOps 工作流集成:
# SparkApplication CRD 示例
apiVersion: sparkoperator.k8s.io/v1beta2
kind: SparkApplication
metadata:
name: sales-analytics
spec:
type: Python
mode: cluster
image: apache/spark:v4.0.0
mainApplicationFile: s3a://bucket/apps/sales_analytics.py
driver:
cores: 2
memory: 4g
executor:
cores: 4
instances: 20
memory: 8g
11.4 监控与日志
# 配置历史服务器,查看已结束作业的 UI
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://namenode/spark-logs"
$SPARK_HOME/sbin/start-history-server.sh
# 访问 http://<host>:18080 查看历史作业
Spark 4.0 引入的 结构化日志 将日志输出为结构化格式(如 JSON),便于接入 ELK、Loki 等日志系统:
spark-submit \
--conf spark.log.structuredLogging.enabled=true \
--conf spark.log.structuredLogging.format=json \
your_app.py
十二、综合实战项目
本章通过一个完整的电商分析项目,串联前面所学的知识点。场景:处理电商交易日志,生成销售报表和实时监控。
12.1 项目架构
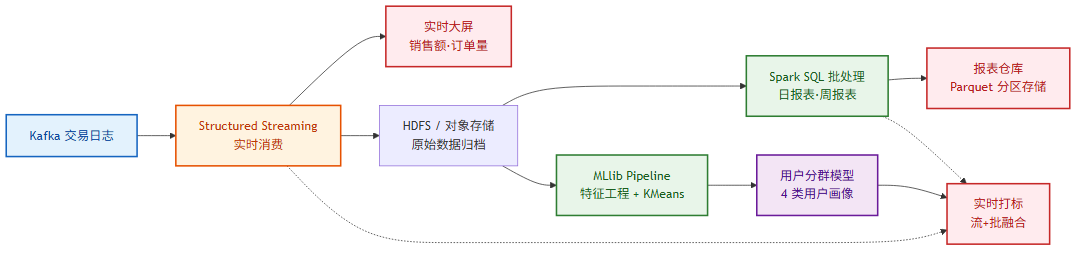
12.2 批处理层:生成日报表
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, sum, count, avg, to_date, current_date
spark = SparkSession.builder \
.appName("EcommerceBatch") \
.config("spark.sql.adaptive.enabled", "true") \
.config("spark.sql.shuffle.partitions", 200) \
.getOrCreate()
# 读取当日交易数据
transactions = spark.read.parquet("hdfs://namenode/data/transactions") \
.filter(col("ts") >= to_date(current_date()))
# 用户维度报表
user_report = transactions.groupBy("user_id").agg(
count("*").alias("order_count"),
sum("amount").alias("total_spent"),
avg("amount").alias("avg_order_value")
)
# 商品维度报表
product_report = transactions.groupBy("product_id", "category").agg(
count("*").alias("sales_count"),
sum("amount").alias("revenue")
).orderBy(col("revenue").desc())
# 写入数据仓库(分区存储)
product_report.write \
.mode("overwrite") \
.partitionBy("category") \
.parquet("warehouse/product_daily_report")
12.3 流处理层:实时监控
from pyspark.sql.functions import window, col, from_json
from pyspark.sql.types import StructType, StructField, StringType, DoubleType, TimestampType
# Kafka 流
schema = StructType([
StructField("user_id", StringType()),
StructField("product_id", StringType()),
StructField("amount", DoubleType()),
StructField("ts", TimestampType())
])
stream = spark.readStream.format("kafka") \
.option("kafka.bootstrap.servers", "kafka:9092") \
.option("subscribe", "transactions") \
.load() \
.select(from_json(col("value").cast("string"), schema).alias("d")) \
.select("d.*")
# 实时销售额(1 分钟窗口)
realtime_sales = stream \
.withWatermark("ts", "5 minutes") \
.groupBy(window(col("ts"), "1 minute")) \
.agg(sum("amount").alias("sales"), count("*").alias("orders"))
# 写入 Redis 供大屏读取
def write_to_redis(batch_df, batch_id):
rows = batch_df.collect()
for row in rows:
# 写入 Redis 逻辑
pass
query = realtime_sales.writeStream \
.foreachBatch(write_to_redis) \
.outputMode("update") \
.option("checkpointLocation", "hdfs://namenode/checkpoint/realtime_sales") \
.trigger(processingTime="30 seconds") \
.start()
query.awaitTermination()
12.4 机器学习层:用户分群
from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler, StandardScaler
from pyspark.ml.clustering import KMeans
# 准备特征
features = user_report.select(
"order_count", "total_spent", "avg_order_value"
)
assembler = VectorAssembler(
inputCols=["order_count", "total_spent", "avg_order_value"],
outputCol="raw_features"
)
scaler = StandardScaler(
inputCol="raw_features",
outputCol="features",
withMean=True,
withStd=True
)
kmeans = KMeans(k=4, seed=42, featuresCol="features", predictionCol="cluster")
pipeline = Pipeline(stages=[assembler, scaler, kmeans])
model = pipeline.fit(features)
# 输出分群结果
clustered = model.transform(user_report)
clustered.groupBy("cluster").agg(
count("*").alias("user_cnt"),
avg("total_spent").alias("avg_spent")
).show()
# 保存模型,供流处理层实时打标
model.write().overwrite().save("hdfs://namenode/models/user_segmentation")
这个项目把批处理、流处理、机器学习三个模块整合在一个 Spark 应用中,体现了"统一引擎"的价值——同一份数据、同一套 API,覆盖了离线分析、实时监控和智能分群三种场景。
十三、学习路线与进阶建议
13.1 阶段化学习路径

入门阶段(1-2 周): 重点掌握环境搭建、DataFrame 基本操作、Spark SQL。能独立完成读取文件、过滤聚合、写出结果的批处理任务。这个阶段不必纠结 RDD,直接从 DataFrame 上手效率更高。
进阶阶段(2-4 周): 深入理解 Spark 运行架构、Shuffle 机制、AQE 原理。学习 Structured Streaming 和 MLlib。能处理数据倾斜、小文件等常见问题,具备基本的性能调优能力。
精通阶段(持续): 研究 Catalyst 优化器和 Tungsten 执行引擎的内部原理。掌握集群部署、资源调度、监控运维。能根据业务场景设计端到端的数据管道,并在性能与成本间做出合理权衡。
13.2 常见陷阱
- 过度使用
collect():把大数据集拉到 Driver 会导致 OOM。需要查看数据用take(n)或show()。 - 缓存后忘记释放:内存资源有限,用完的缓存应当
unpersist()。 - 宽窄依赖不分:错误地认为
map会触发 Shuffle,或对需要 Shuffle 的操作不调整分区数。 - 忽视序列化:在 RDD 中使用 Python 对象时,未考虑序列化开销会导致性能骤降。
- 小文件过多:写入时未合理设置分区数,产生大量小文件,拖慢后续读取。
13.3 进阶资源
- 官方文档:
spark.apache.org/docs/latest,最权威的参考,每个版本更新都应通读 Release Notes。 - 源码阅读:从
SparkSession、DataFrame、QueryExecution入口出发,理解一次 SQL 查询从解析到执行的完整链路。 - 社区参与:关注 Spark JIRA 和邮件列表,参与 issue 讨论是理解设计意图的最佳途径。
- 生产实践:在大规模数据上遇到的性能问题,往往是文档中不会写的实战经验。建立自己的调优案例库,比记住任何参数都重要。
Spark 的学习曲线在"会用"到"用得好"之间最为陡峭,分水岭在于是否真正理解了 Shuffle、内存管理和查询优化这三个底层机制。当你能从 Spark UI 的执行计划中读懂瓶颈所在,并且知道用什么手段去改善它时,就算是真正入门了精通之路。
评论区